 Linux笔记-Shell
Linux笔记-Shell
Table of Contents generated with DocToc (opens new window)
# 常用命令:文件搜索命令
# find命令
命令名称: find
命令所在路径:/bin/find
执行权限:所有用户
语法: find[搜索范围][匹配条件]
功能描述:文件搜索
2
3
4
5
find /ect -name init(是精准搜索)
find /ect -name * init * 相当于模糊查询; init:以init开头的;init???:已init开头,后面三个字母的。*
在目录/etc中查找文件int (-iname 不区分大小写);
find / -size +204800 在根目录下查找大于100MB的文件;+n:大于 -n:小于 n:等于
find /home -user shenchao 在根目录下查找所有者为shenchao的文件;-group根据所属组查找
# Shell
输出命令 echo [选项] [输出内容]
选项:-e : 支持反斜线控制的字符转换
# 编写shell脚本
首先第一行要写
#!/bin/Bash 作为标识,来表示这是一个shell脚本文件
示例:
#!/bin/Bash
#first
#Author: zdk
echo -e "hello world"
#注意:输出内容在双引号中时,不要加!,因为!在shell语法中是有特殊作用的符号;要加的话,用单引号
2
3
4
5
6
7
# 脚本执行方式
- 赋予执行权限,直接运行
- chmod 755 hello.sh
- ./hello.sh
- 通过bash调用执行脚本
- bash hello.sh
# Bash基本功能
# 历史命令
history [选项] [历史命令保存文件] 默认历史命令保存文件在:vim /root/.bash_history
选项:-c:清空历史命令
-w: 把缓存中的历史命令写入历史命令保存文件
历史命令默认会保存1000条,可以在环境变量配置文件/etc/profile中进行修改,其中HISTSIZE变量表示历史命令保存的最大条数
# 历史命令的调用
- 使用上、下箭头调佣以前的历史命令
- 使用"!n":重复执行第n条历史命令
- 使用"!!":重复执行上一条命令
- 使用"!子串":重复执行最后一条以该字串开头的命令
# 命令与文件补全
- 在Bash中,命令与文件补全是非常方便与常用的功能,我们只要在输入命令或文件时,按“Tab”键就会自动进行补全
- 按一次如果没有补全,可能证明有多个以此字串开头的命令或文件,再按一下tab,即可弹出命令或文件列表
# 命令别名
- 设定命令别名:alias 别名='原命令'
- 查询命令别名 alias
- whereis 命令,这个语句可以找到命令所在的文件位置
- 注意命令执行顺序
- 第一顺位执行用绝对路径或相对路径执行的命令
- 第二顺位执行别名
- 第三顺位执行bash的内部命令
- 第四顺位执行按照$PATH环境变量定义的目录查找顺序找到的第一个命令
- 想要别名永久生效:将别名命令写入 vim /root/.bashrc文件中
- 删除别名:unalias 别名
# 常用快捷键
- ctrl+A:把光标移动到命令行开头。如果我们输入的命令过长,想要把光标移动到命令行开头时使用。
- ctrl+E:把光标移动到命令行结尾。
- ctrl+C:强制终止当前的命令。
- ctrl+H:清屏,相当于clear命令。
- ctrl+U:删除或剪切光标之前的命令。我输入了一行很长的命令,不用使用退格键一个一个字符的删除,使用这个快捷键会更加方便
- ctrl+K:删除或剪切光标之后的内容。
- ctrl+Y:粘贴ctrl+U或ctrl+K剪切的内容。
- ctrl+R:在历史命令中搜索,按下ctrl+R之后,就会出现搜索界面,只要输入搜索内容,就会从历史命令中搜索。
- ctrl+D:退出当前终端。
- ctrl+Z:暂停,并放入后台。这个快捷键牵扯工作管理的内容,我们在系统管理章节详细介绍。
- ctrl+S:暂停屏幕输出。
- ctrl+Q:恢复屏幕输出。
# 输入输出重定向
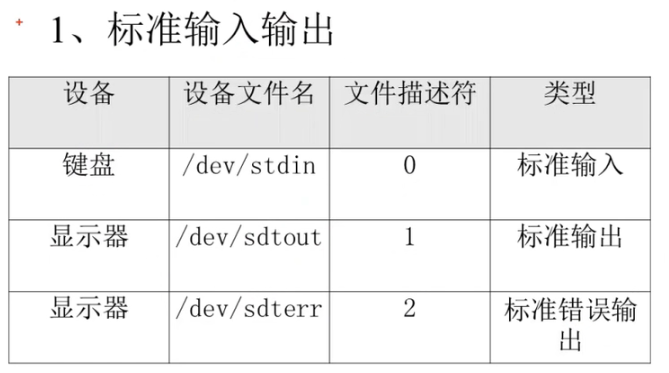
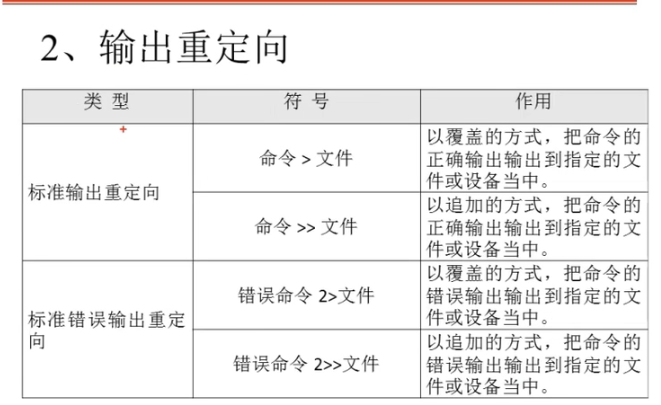
- 将正确命令的结果重定向写入一个文件,如:ls > abc (>表示每次写入会覆盖原来的内容);如果使用ls >> abc,则不会覆盖,而是在原来的末尾追加上新的内容
- 将错误命令写入文件:需要在>或>>之前加一个2(代表错误输出重定向,会把报错信息写入指定的文件),注意,2和>、>>之间没有空格,例如:lst 2>> abc

将正确、错误命令都写入到同一文件中:
如:lst >> bcd 2>&1,ls >> bcd 2>&1(即表示将正误命令信息都写入到文件bcd中)
将所有命令写入一个空的地方,即所有命令的结果都不保存:ls &>/dev/null
将正误命令分开保存: 命令 >>文件1 2>>文件2 (如果命令正确,会被保存到文件1,如果错误,会被保存到文件2)

使用方法:命令 < 文件 把文件作为命令的输入,如:wc < hello.sh
# 多命令顺序执行和管道符

dd if=输入文件 of=输出文件 bs=字节数 count=个数 (dd相当于磁盘拷贝命令,可以复制各种文件或进行磁盘复制)
选项:
if=输入文件 指定源文件或源设备
of=输出文件 指定目标文件或目标设备
bs=字节数 指定一次输入/输出多少字节,即把这些字节看做一个数据块
count=个数 指定输入/输出多少个数据块
例子:date;dd if=/dev/zero of=/root/testfile bs=1k count=100000;date
date中间的命令表示创建一个100m的文件testfile,两个date就可以知道创建所需的时间
前面的命令执行成功,后面的命令才会执行:
格式:命令1 && 命令2 && 命令3 ......
前面的命令执行失败,后面的命令才会执行:
格式:命令1 || 命令2 || 命令3 ......:命令 && echo yes || echo no
# 管道符
命令格式:命令1 | 命令2 :命令1的正确输出作为命令2的操作对象
例子:ll -a /etc/ | more、netstat -an | grep "ESTABLISHED"。netstat :查询所有的网络服务
grep命令:grep [选项] "搜索内容"
文件名
选项:-i:忽略大小写
-n:输出行号
-v:反向查找
--color=auto 把搜索出的关键字用颜色显示
grep "hel" ~/Documents/hello.sh
grep -n --color=auto "hel" ~/Documents/hello.sh
netstat -an | grep ESTABLISHED
2
3
# 通配符和其他特殊符号
# 通配符
? :匹配一个任意字符;例如:ls ?abc:
*:匹配0个或任意多个任意字符,也就是可以匹配任何内容 ;例如:ls *abc,找到任意字符后面有且仅为abc的文件。 ls * abc *即常规意义上的模糊查询
[]:匹配括号中任意一个字符。例如:[abc]代表一定匹配一个字符,或者是a或者是b或者是c
[-]:匹配括号中任意一个字符,-代表一个范围。例如:[a-z]代表匹配一个小写字母。ls [ 0-9 ]abc
[^]:逻辑非,表示匹配不是中括号内的一个字符。例如:[ ^0-9 ]代表匹配一个不是数字的字符。
例如 ls [ ^0-9 ]abc
# 其他特殊符号
' ':单引号、在单引号中所有的特殊符号,如$和`(反引号)等都没有特殊含义,只会是字符

