RabbitMQ - 简单案例
RabbitMQ - 简单案例
# Hello world
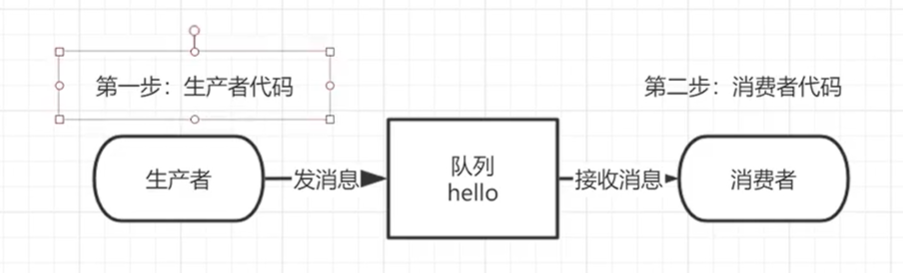
我们将用 Java 编写两个程序。发送单个消息的生产者和接收消息并打印出来的消费者
在下图中,“ P” 是我们的生产者,“ C” 是我们的消费者。中间的框是一个队列 RabbitMQ 代表使用者保留的消息缓冲区

连接的时候,需要开启 5672 端口
- 依赖
pom.xml
<!--指定 jdk 编译版本-->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<!--rabbitmq 依赖客户端-->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.8.0</version>
</dependency>
<!--操作文件流的一个依赖-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- 消息生产者
发送消息
package com.zdk.one;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
import java.util.concurrent.TimeoutException;
/**
* @author zdk
* @date 2022/5/1 17:43
* 生产者
*/
public class Producer {
private static final String QUEUE_NAME = "hello_world";
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("211.69.238.77");
connectionFactory.setUsername("admin");
connectionFactory.setPassword("123456");
//创建连接
Connection connection = connectionFactory.newConnection();
//连接里创建信道
Channel channel = connection.createChannel();
//生成一个队列
channel.queueDeclare(QUEUE_NAME,false,false, false, null);
/**
* 发送消息
*/
String message;
Scanner cin = new Scanner(System.in);
while (cin.hasNext()){
message = cin.next();
//发布消息
channel.basicPublish("", QUEUE_NAME, null, message.getBytes(StandardCharsets.UTF_8));
System.out.println("消息发送完毕");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
- 消息消费者
获取“生产者”发出的消息
package com.zdk.one;
import com.rabbitmq.client.*;
/**
* @author zdk
* @date 2022/5/1 17:43
* 消费者
*/
public class Consumer {
private static final String QUEUE_NAME = "hello_world";
public static void main(String[] args) throws Exception {
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("211.69.238.77");
connectionFactory.setUsername("admin");
connectionFactory.setPassword("123456");
//创建连接
Connection connection = connectionFactory.newConnection();
//连接里创建信道
Channel channel = connection.createChannel();
System.out.println("等待接收消息.........");
//推送来的消息如何被消费的回调
DeliverCallback deliverCallback = (consumerTag, message) -> {
String msg = new String(message.getBody());
System.out.println(msg);
};
//取消消费的一个回调接口 比如在消费的时候队列被删除掉了
CancelCallback cancelCallback = (consumerTag) -> System.out.println("消息消费被中断");
/**
* 1.消费哪一个队列
* 2.是否自动应答
* 3.消费者如何进行消费的回调
* 4.消费者取消了消费的回调
*/
channel.basicConsume(QUEUE_NAME, true,deliverCallback,cancelCallback);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 测试结果
# Work Queues
Work Queues——工作队列(又称任务队列)的主要思想是避免立即执行资源密集型任务,而不得不等待它完成。 相反我们安排任务在之后执行。我们把任务封装为消息并将其发送到队列。在后台运行的工作进 程将弹出任务并最终执行作业。当有多个工作线程时,这些工作线程将一起处理这些任务。
# 轮训分发消息
在这个案例中我们会启动两个工作线程,一个消息发送线程,我们来看看他们两个工作线程是如何工作的。
1、抽取工具类
package com.zdk.utils;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
/**
* @author zdk
* @date 2022/5/1 19:58
*/
@SuppressWarnings("all")
public class RabbitMQUtils {
public static Channel getChannel() throws Exception{
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("211.69.238.77");
connectionFactory.setUsername("admin");
connectionFactory.setPassword("123456");
Connection connection = connectionFactory.newConnection();
return connection.createChannel();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2、启动两个工作线程来接受消息
package com.zdk.workQueues;
import com.rabbitmq.client.CancelCallback;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import com.zdk.utils.RabbitMQUtils;
/**
* @author zdk
* @date 2022/5/1 20:00
*/
public class Work {
private static final String QUEUE_NAME = "hello_world";
public static void main(String[] args) throws Exception{
Channel channel = RabbitMQUtils.getChannel();
System.out.println("work2等待接收消息.........");
//推送来的消息如何被消费的回调
DeliverCallback deliverCallback = (consumerTag, message) -> {
String msg = new String(message.getBody());
System.out.println(msg);
};
CancelCallback cancelCallback = (consumerTag) -> System.out.println(consumerTag+"消息消费被中断");
channel.basicConsume(QUEUE_NAME, true,deliverCallback,cancelCallback);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
选中 Allow multiple instances 
启动后
3、启动一个发送消息线程
启动上面的Producer即可
- 结果展示
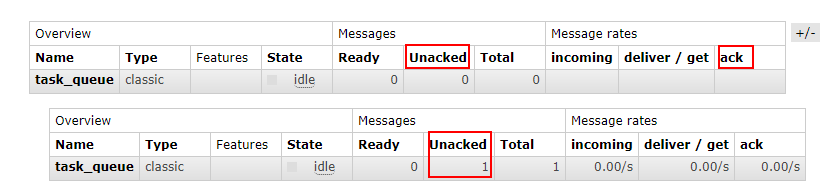
通过程序执行发现生产者总共发送 4 个消息,消费者 1 和消费者 2 分别分得两个消息,并且是按照有序的一个接收一次消息

# 消息应答
消费者完成一个任务可能需要一段时间,如果其中一个消费者处理一个长的任务并仅只完成了部分突然它挂掉了,会发生什么情况。RabbitMQ 一旦向消费者传递了一条消息,便立即将该消息标记为删除。在这种情况下,突然有个消费者挂掉了,我们将丢失正在处理的消息。以及后续发送给该消费这的消息,因为它无法接收到。
为了保证消息在发送过程中不丢失,引入消息应答机制,消息应答就是:消费者在接收到消息并且处理该消息之后,告诉 rabbitmq 它已经处理了,rabbitmq 可以把该消息删除了。
# 自动应答
消息发送后立即被认为已经传送成功,这种模式需要在高吞吐量和数据传输安全性方面做权衡,因为这种模式如果消息在接收到之前,消费者那边出现连接或者 channel 关闭,那么消息就丢失 了,当然另一方面这种模式消费者那边可以传递过载的消息,没有对传递的消息数量进行限制,当然这样有可能使得消费者这边由于接收太多还来不及处理的消息,导致这些消息的积压,最终使 得内存耗尽,最终这些消费者线程被操作系统杀死,所以这种模式仅适用在消费者可以高效并以 某种速率能够处理这些消息的情况下使用。
# 手动消息应答的方法
Channel.basicAck(用于肯定确认)
RabbitMQ 已知道该消息并且成功的处理消息,可以将其丢弃了
Channel.basicNack(用于否定确认)
Channel.basicReject(用于否定确认)
与 Channel.basicNack 相比少一个参数,不处理该消息了直接拒绝,可以将其丢弃了
Multiple 的解释:
手动应答的好处是可以批量应答并且减少网络拥堵
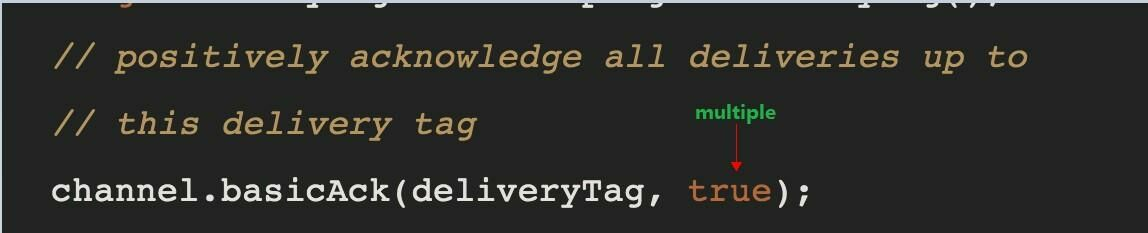
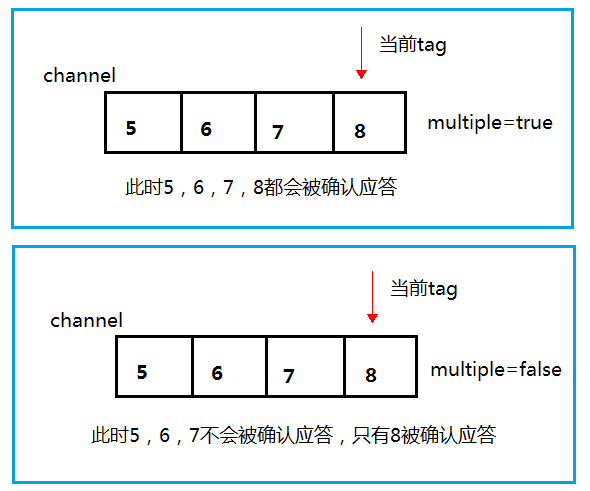
true 代表批量应答 channel 上未应答的消息
比如说 channel 上有传送 tag 的消息 5,6,7,8 当前 tag 是8 那么此时5-8 的这些还未应答的消息都会被确认收到消息应答
false 同上面相比只会应答 tag=8 的消息 5,6,7 这三个消息依然不会被确认收到消息应答
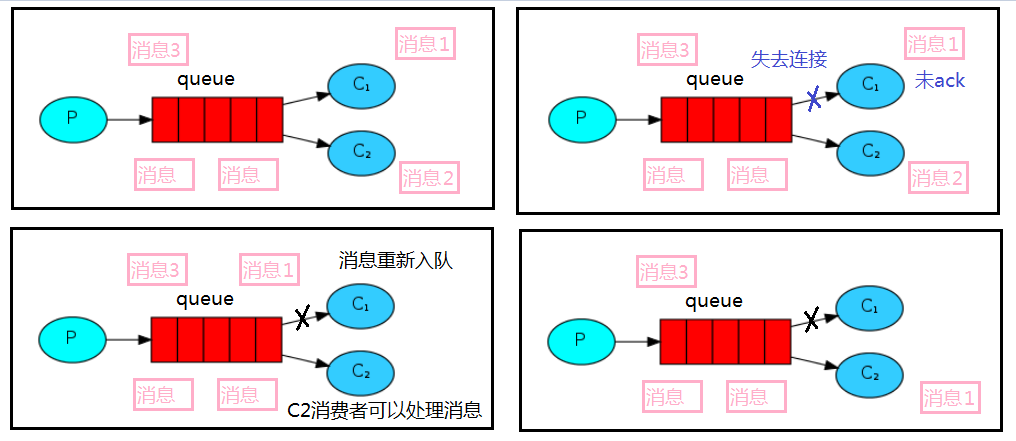
# 消息自动重新入队
如果消费者由于某些原因失去连接(其通道已关闭,连接已关闭或 TCP 连接丢失),导致消息未发送 ACK 确认,RabbitMQ 将了解到消息未完全处理,并将对其重新排队。如果此时其他消费者可以处理,它将很快将其重新分发给另一个消费者。这样,即使某个消费者偶尔死亡,也可以确保不会丢失任何消息。
# 消息手动应答代码
默认消息采用的是自动应答,所以我们要想实现消息消费过程中不丢失,需要把自动应答改为手动应答
消费者在上面代码的基础上增加了以下内容
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
消息生产者:
与上面的Producer一样
消费者 01:
package com.zdk.ack;
import com.rabbitmq.client.CancelCallback;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import com.zdk.utils.RabbitMQUtils;
import java.util.concurrent.TimeUnit;
/**
* @author zdk
* @date 2022/5/1 20:33
*/
public class ConsumerAck {
private static final String QUEUE_NAME = "hello_world";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
System.out.println("work1等待接收消息(处理时间短).........");
//System.out.println("work2等待接收消息(处理时间长).........");
//推送来的消息如何被消费的回调
DeliverCallback deliverCallback = (consumerTag, message) -> {
try {
TimeUnit.SECONDS.sleep(1);
//TimeUnit.SECONDS.sleep(30);
} catch (InterruptedException e) {
e.printStackTrace();
}
String msg = new String(message.getBody());
System.out.println("work1收到消息:"+msg);
//System.out.println("work2收到消息:"+msg);
//multiple表示是否批量确认,类似于tcp的确认,认为tag之前的tag都完成了消费,把它们都一起确认了
channel.basicAck(message.getEnvelope().getDeliveryTag(), false);
};
CancelCallback cancelCallback = (consumerTag) -> System.out.println(consumerTag+"消息消费被中断");
channel.basicConsume(QUEUE_NAME,false,deliverCallback,cancelCallback);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
消费者 02:
把sleep时间改成30秒,work的数字改一下
手动应答效果演示
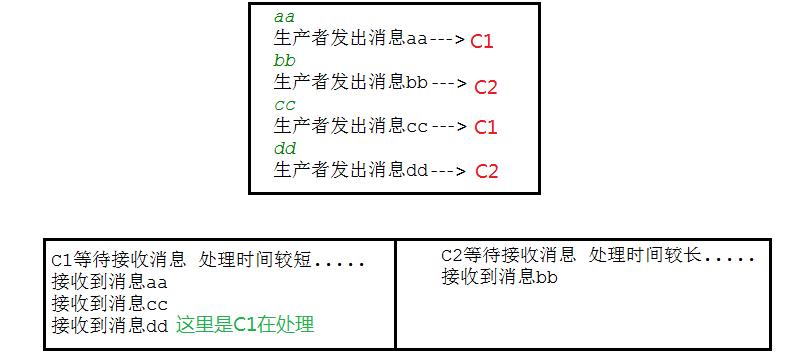
正常情况下消息发送方发送两个消息 C1 和 C2 分别接收到消息并进行处理

在发送者发送消息 dd,发出消息之后的把 C2 消费者停掉,按理说该 C2 来处理该消息,但是由于它处理时间较长,在还未处理完,也就是说 C2 还没有执行 ack 代码的时候,C2 被停掉了, 此时会看到消息被 C1 接收到了,说明消息 dd 被重新入队,然后分配给能处理消息的 C1 处理了
# RabbitMQ 持久化
当 RabbitMQ 服务停掉以后,消息生产者发送过来的消息不丢失要如何保障?默认情况下 RabbitMQ 退出或由于某种原因崩溃时,它忽视队列和消息,除非告知它不要这样做。确保消息不会丢失需要做两件事:我们需要将队列和消息都标记为持久化。
队列如何实现持久化
之前我们创建的队列都是非持久化的,rabbitmq 如果重启的化,该队列就会被删除掉,如果要队列实现持久化需要在声明队列的时候把 durable 参数设置为持久化
//让队列持久化
boolean durable = true;
//声明队列
channel.queueDeclare(TASK_QUEUE_NAME, durable, false, false, null);
2
3
4
注意:如果之前声明的队列不是持久化的,需要把原先队列先删除,或者重新创建一个持久化的队列,不然就会出现错误
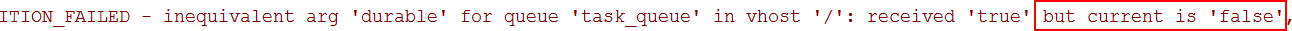
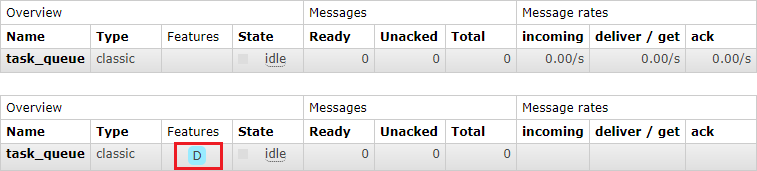
以下为控制台中持久化与非持久化队列的 UI 显示区、
消息实现持久化
需要在消息生产者修改代码,MessageProperties.PERSISTENT_TEXT_PLAIN 添加这个属性。

将消息标记为持久化并不能完全保证不会丢失消息。尽管它告诉 RabbitMQ 将消息保存到磁盘,但是这里依然存在当消息刚准备存储在磁盘的时候 但是还没有存储完,消息还在缓存的一个间隔点。此时并没 有真正写入磁盘。持久性保证并不强,但是对于我们的简单任务队列而言,这已经绰绰有余了。
如果需要更强有力的持久化策略,参考后边课件发布确认章节。
# 公平分发
在最开始的时候我们学习到 RabbitMQ 分发消息采用的轮训分发,但是在某种场景下这种策略并不是很好,比方说有两个消费者在处理任务,其中有个消费者 1 处理任务的速度非常快,而另外一个消费者 2 处理速度却很慢,这个时候我们还是采用轮训分发的话就会让处理速度快的这个消费者很大一部分时间处于空闲状态,而处理慢的那个消费者一直在干活,这种分配方式在这种情况下其实就不太好,但是 RabbitMQ 并不知道这种情况它依然很公平的进行分发。
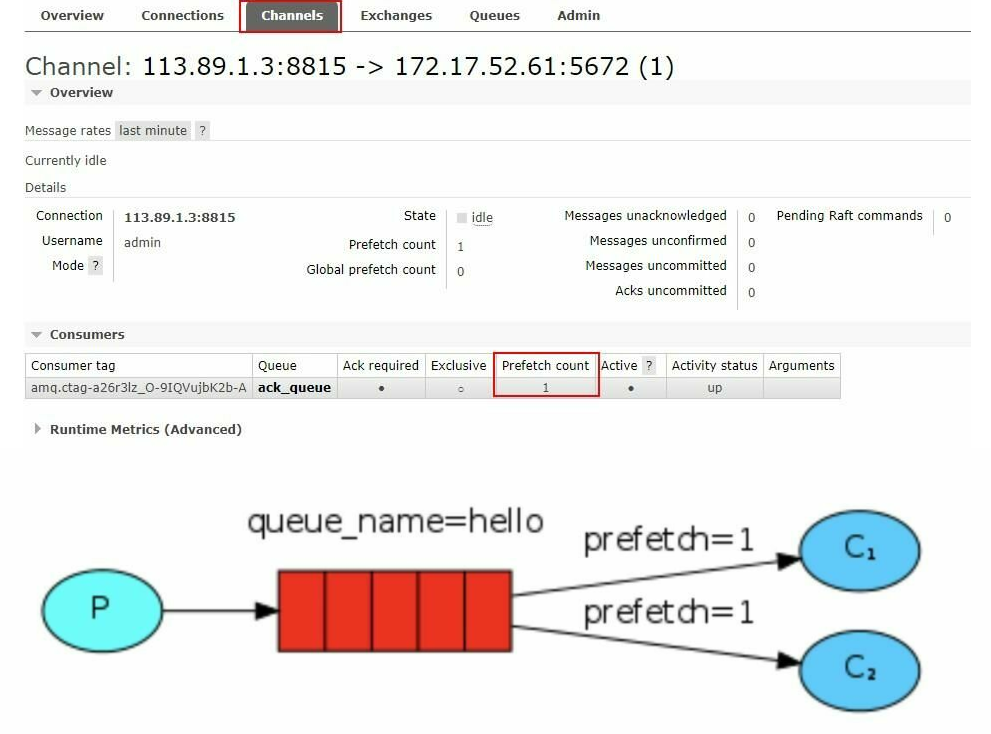
为了避免这种情况,在消费者中消费之前,我们可以设置参数 channel.basicQos(int prefetchCount);
//公平分发
int prefetchCount = 1;
channel.basicQos(prefetchCount);
//采用手动应答
boolean autoAck = false;
channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, cancelCallback);
2
3
4
5
6
注意
这里其实是这个意思,课程上没讲明白。basicQos方法的参数prefetchCount应该是限制当前这个消费者信道的信道上允许的未确认消息的最大数量,如果未应答数量大于等于这个值,那么这个消费者将不会被分发到下一个消息,而是交给未达到最大数量的信道去处理。
所以我们要实现公平分发,就让消费者的prefetchCount相等即可,那么它们能同时处理的最大消息数就会是一样的,谓之公平,但处理得快的消费者仍会处理更多的消息,谓之不公平
当然如果所有的消费者都没有完成手上任务,队列还在不停的添加新任务,队列有可能就会遇到队列被撑满的情况,这个时候就只能添加新的worker或者改变其他存储任务的策略
# 例子
注意,这个机制是要基于手动确认来实现的,如果自动确认的话就和轮询一样了,消息可能会堆积
通过消费者端设置其能维持的最大未确认消息数来实现公平分发channel.basicQos(int prefetchCount);1
总共发送了a、b、c、d、e、f六个消息,处理时间短的消费者运行的未确认消息数量限制为3,时间长的消费者限制为2
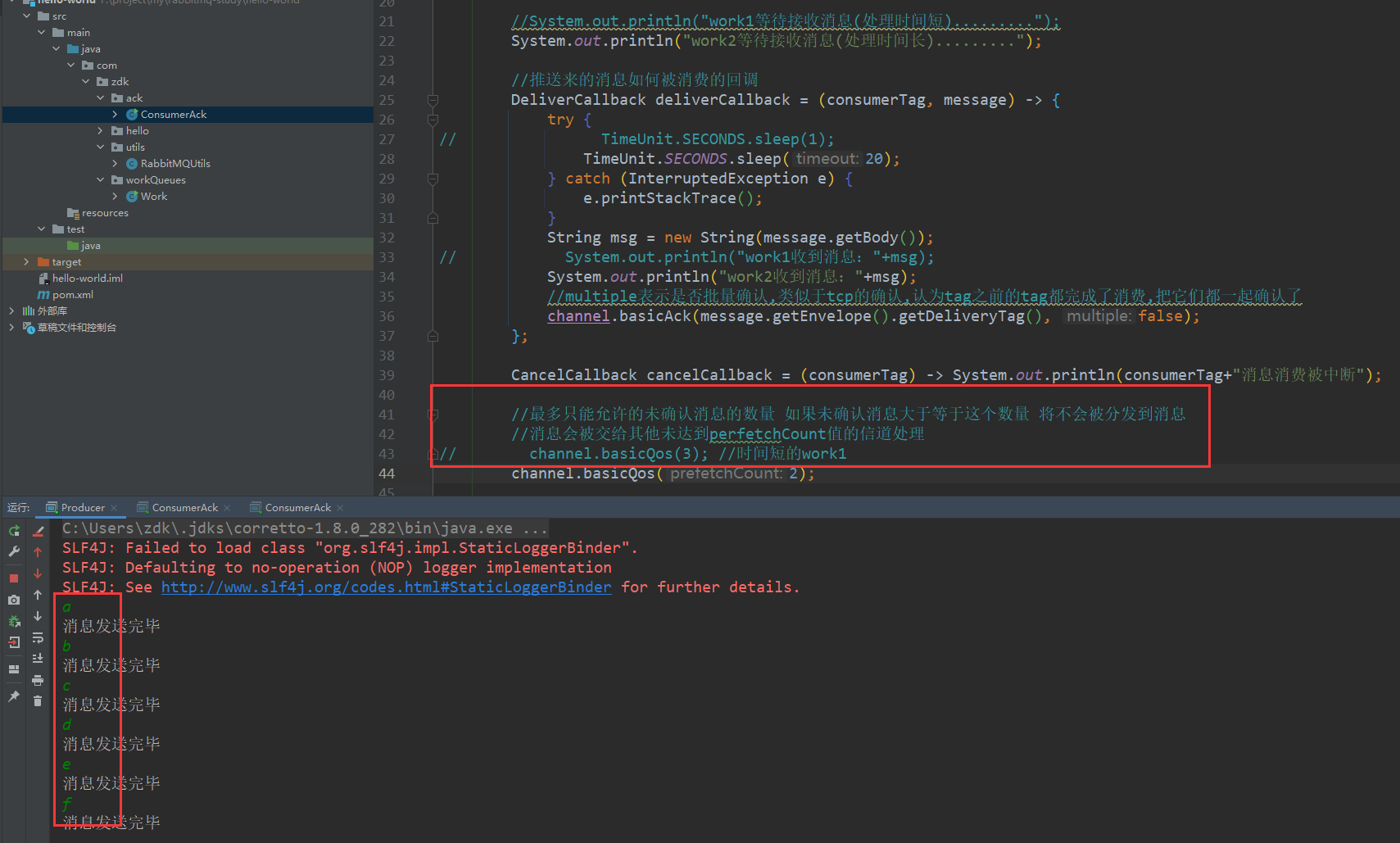
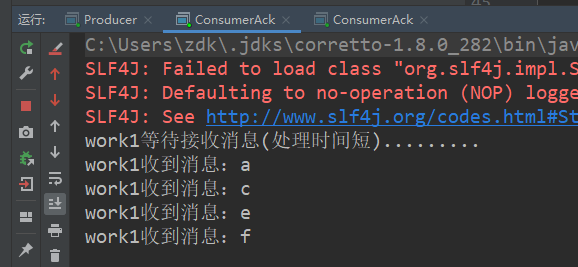
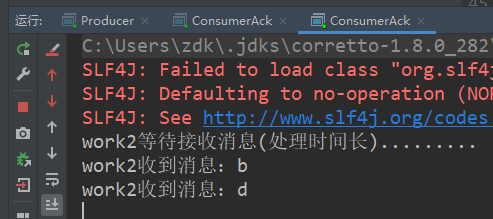
而运行的结果是:
提示
当未达到perfetchCount的时候,是轮询的,即一个消费者分发一个消息,work2因为处理得慢,所以很快未确认消息达到了设定的最大值2,所以它不能再消费消息了,剩下的消息都被分发给了work1
# 预取值分发
带权的消息分发
本身消息的发送就是异步发送的,所以在任何时候,channel 上肯定不止只有一个消息,另外,来自消费者的手动确认本质上也是异步的。因此这里就存在一个未确认的消息缓冲区,因此希望开发人员能限制此缓冲区的大小,以避免缓冲区里面无限制的未确认消息问题。这个时候就可以通过使用
basic.Qos(int prefetchCount)方法设 置“预取计数”值来完成。
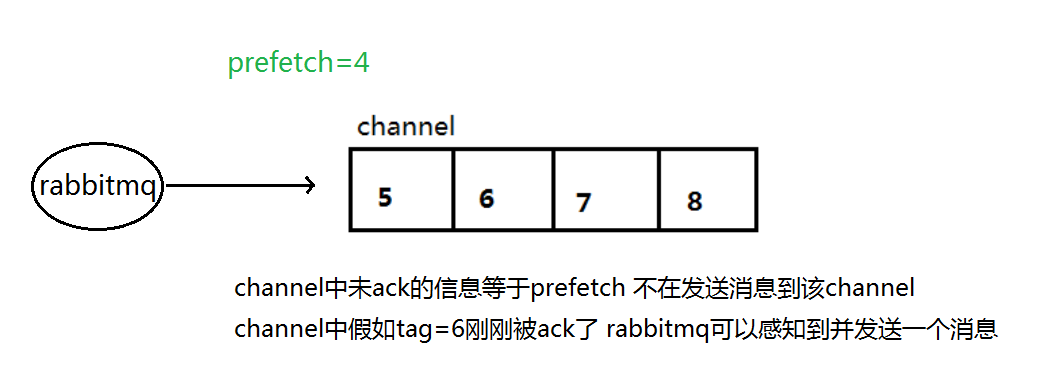
该值定义通道上允许的未确认消息的最大数量。一旦数量达到配置的数量, RabbitMQ 将停止在通道上传递更多消息,除非至少有一个未处理的消息被确认,例如,假设在通道上有未确认的消息 5、6、7,8,并且通道的预取计数设置为 4,此时RabbitMQ 将不会在该通道上再传递任何消息,除非至少有一个未应答的消息被 ack。比方说 tag=6 这个消息刚刚被确认 ACK,RabbitMQ 将会感知 这个情况到并再发送一条消息。消息应答和 QoS 预取值对用户吞吐量有重大影响。
通常,增加预取将提高 向消费者传递消息的速度。虽然自动应答传输消息速率是最佳的,但是,在这种情况下已传递但尚未处理的消息的数量也会增加,从而增加了消费者的 RAM 消耗(随机存取存储器)应该小心使用具有无限预处理的自动确认模式或手动确认模式,消费者消费了大量的消息如果没有确认的话,会导致消费者连接节点的 内存消耗变大,所以找到合适的预取值是一个反复试验的过程,不同的负载该值取值也不同。
100 到 300 范 围内的值通常可提供最佳的吞吐量,并且不会给消费者带来太大的风险。
预取值为 1 是最保守的。当然这将使吞吐量变得很低,特别是消费者连接延迟很严重的情况下,特别是在消费者连接等待时间较长的环境 中。对于大多数应用来说,稍微高一点的值是最佳的。