 HTTP、HTTPS
HTTP、HTTPS
Table of Contents generated with DocToc (opens new window)
# 1.HTTP和HTTPS的基本概念和区别
HTTP:HTTP的中文叫做超文本传输协议,它负责完成客户端到服务端的一系列操作,是专门用来传输注入HTML的超媒体文档等web内容的协议,它是基于传输层的TCP协议的应用层协议
HTTPS:HTTPS是基于安全套接字的http协议,也可以理解为是HTTP+SSL/TLS(数字证书)的组合
HTTP和HTTPS的区别:
- HTTP 的 URL 以 http:// 开头,而 HTTPS 的 URL 以 https:// 开头
- HTTP 是不安全的,而 HTTPS 是安全的
- HTTP 标准端口是 80 ,而 HTTPS 的标准端口是 443
- 在 OSI 网络模型中,HTTPS的加密是在传输层完成的,因为SSL是位于传输层的,TLS的前身是SSL,所以同理
- HTTP无需认证证书,而HTTPS需要认证证书
小结:简单来说HTTP是用来进行html等超媒体传输的,但是HTTP不安全,为了安全,使用证书SSL和HTTP的方式进行数据传输,也就是HTTPS
# 2.HTTP
# 2.1 HTTP协议的组成
请求报文包含三部分:
- 请求行:包含请求方法、URI、HTTP版本信息
- 请求首部字段
- 请求内容实体
响应报文包含三部分:
- 状态行:包含HTTP版本、状态码、状态码的原因短语
- 响应首部字段
- 响应内容实体
# 2.2 说一下HTTP协议中302状态(阿里经常问)
- http协议中,返回状态码302表示重定向。
- 这种情况下,服务器返回的头部信息中会包含一个 Location 字段,内容是重定向到的url。
# 一些常见的HTTP状态码
| 状态码 | 描述 |
|---|---|
| 200 OK | 表示从客户端发送给服务器的请求被正常处理并返回 |
| 204 No Content | 表示客户端发送给客户端的请求得到了成功处理,但在返回的响应报文中不含实体的主体部分(没有资源可以返回) |
| 206 Patial Content | 表示客户端进行了范围请求,并且服务器成功执行了这部分的GET请求,响应报文中包含由Content-Range指定范围的实体内容 |
| 301 Moved Permanently | 永久性重定向,表示请求的资源被分配了新的URL,之后应使用更改的URL |
| 302 Found | 临时性重定向,表示请求的资源被分配了新的URL,希望本次访问使用新的URL;301与302的区别:前者是永久移动,后者是临时移动(之后可能还会更改URL),这种情况下,服务器返回的头部信息中会包含一个 Location 字段,内容是重定向到的url |
| 303 See Other | 表示请求的资源被分配了新的URL,应使用GET方法定向获取请求的资源;302与303的区别:后者明确表示客户端应当采用GET方式获取资源 |
| 304 Not Modified | 表示客户端发送附带条件(是指采用GET方法的请求报文中包含if-Match、If-Modified-Since、If-None-Match、If-Range、If-Unmodified-Since中任一首部)的请求时,服务器端允许访问资源,但是请求为满足条件的情况下返回改状态码 |
| 307 Temporary Redirect | 临时重定向,与303有着相同的含义,307会遵照浏览器标准不会从POST变成GET;(不同浏览器可能会出现不同的情况) |
| 400 Bad Request | 表示请求报文中存在语法错误 |
| 401 Unauthorized | 未经许可,需要通过HTTP认证 |
| 403 Forbidden | 服务器拒绝该次访问(访问权限出现问题) |
| 404 Not Found | 表示服务器上无法找到请求的资源,除此之外,也可以在服务器拒绝请求但不想给拒绝原因时使用 |
| 500 Inter Server Error | 表示服务器在执行请求时发生了错误,也有可能是web应用存在的bug或某些临时的错误时 |
| 501 | 服务器不具备完成请求的功能。例如:服务器无法识别请求方法时可能会返回此代码 |
| 502 Bad Getway | 使用https访问http的网站 |
| 503 Server Unavailable | 表示服务器暂时处于超负载或正在进行停机维护,无法处理请求 |
# 2.3 HTTP1.0,1.1,2.0之间的区别和特性
# http1.0:
- 是一种无状态、无连接的应用层协议,每个请求都会新创建一个tcp连接,完成后关闭服务端不跟踪也不记录过去的请求(无状态),但正因频繁创建连接,由于tcp的慢启动(为了不给网络造成拥堵,在首次进行tcp请求的时候,会限制服务端和客户端之间交互数据量的上限,大概为14kb,之后以指数级增长),服务端接受请求,处理完,发送完响应之后就会将tcp连接关闭,这造成了很大的资源浪费,而且http1.0在一个请求接收到响应之后才会接着发送下一个,这也造成了head of line blocking(队头阻塞),现在的浏览器为了解决这个问题,采用了一个页面可以建立多个tcp连接的方式来进行
# http1.1:
- 继承了http1.0的特点,同时改善了http的一些问题,首先是长连接,http1.1新增加了connecion字段,里面可以设置keey-Alive(保持连接)或者close(关闭长连接),避免了每次请求都会新建连接,提高了网络的利用率
- http1.1还增加了Host字段,用来明确表示浏览器要服务器上的哪一个WEB站点,这才实现了在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点,同时还支持了断点续传
- http1.1的管道:可以发送很多请求到服务端,但是服务端必须要按顺序返回响应,由此可以看出http1.1的管道只是把客户端的请求序列变成了服务端的响应序列,还是有问题,很多浏览器并不是很支持
- http1.1还增加了缓存,断点续传
# http2.0 :
采用了二进制分帧(frame),在应用层和传输层之间增加了一个二进制分帧层,也就是把http1.x的header和body使用帧(frame)进行了封装
- 这里明确几个概念:流(stream) : 已经建立上连接的双向字节流(也就是一个请求和其对应的响应) 消息:与逻辑消息对应的完整的一系列数据帧 帧(frame):http2.0进行通信的最小单位,每个帧都会包含一个头部,这个头部会包含当前帧所处的流
多路复用:所有的HTTP2.0通信都在一个TCP连接上完成,这个连接可以承载任意数量的双向数据流,每个数据流都以消息的方式进行发送,这个发送可以使乱序的,然后在通过每个帧头部的流标识符进行组装,同时每个数据流都可以设置优先级,可见http2.0真正实现了并行发送数据,这个是给予二进制分帧来实现的,接下来上一张图片,展示一下一个在一个流中分帧传输的实例
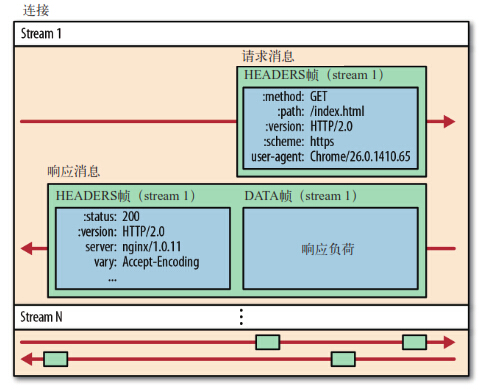
头部压缩:就是和服务端约定头部的数据的编码,来将头部进行压缩后发送,这样就可以增加请求头的容量
# 2.4 get与post的区别
区别一:
- get重点在从服务器上获取资源。
- post重点在向服务器发送数据。
区别二:
- get传输数据是通过URL请求,以field(字段)= value的形式,置于URL后,并用"?"连接,多个请求数据间用"&"连接,如http://127.0.0.1/Test/login.action?name=admin&password=admin,这个过程用户是可见的。
- post传输数据通过Http的post机制,将字段与对应值封存在请求实体中发送给服务器,这个过程对用户是不可见的。
区别三:
- Get传输的数据量小,因为受URL长度限制,但效率较高。
- Post可以传输大量数据,所以上传文件时只能用Post方式。
区别四:
- get是不安全的,因为URL是可见的,可能会泄露私密信息,如密码等。
- post较get安全性较高。
区别五:
- get方式只能支持ASCII字符,向服务器传的中文字符可能会乱码。
- post支持标准字符集,可以正确传递中文字符。
# 2.5 请求头中一般有什么
1)Accept 作用: 浏览器端可以接受的媒体类型 例:Accept :text/html
2)Accept-Encoding: 作用: 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate)
3)Accept-Language 作用: 浏览器申明自己接收的语言。 例:Accept-Language: en-us
4)Connection 例如: Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
5)Host(发送请求时,该报头域是必需的) 作用: 请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的
6)Referer 作用:当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的
7)User-Agent 作用:告诉HTTP服务器, 客户端使用的操作系统 (opens new window)和浏览器的名称和版本
# 2.6 请求和响应常见通用头
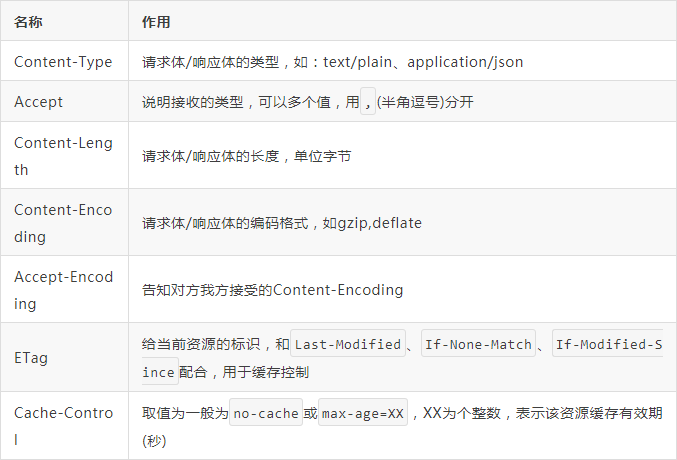
# 2.6.1 Content-Type
Content-Type,内容类型,一般是指网页中存在的Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件。
常见的媒体格式类型如下:
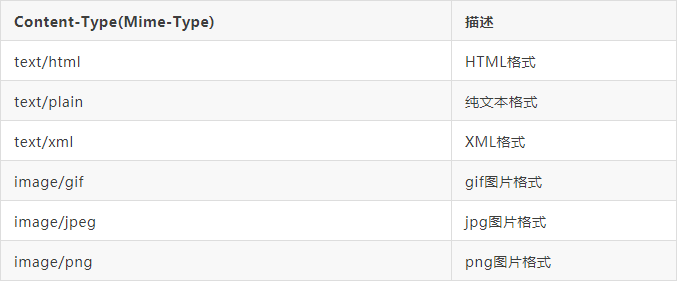
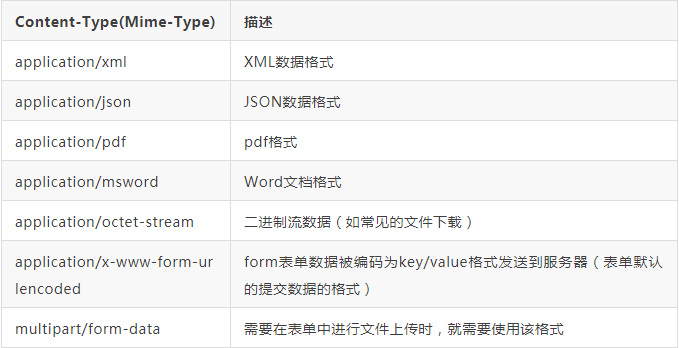
以application开头的媒体格式类型:
# 二、一次完整的http请求发生了什么
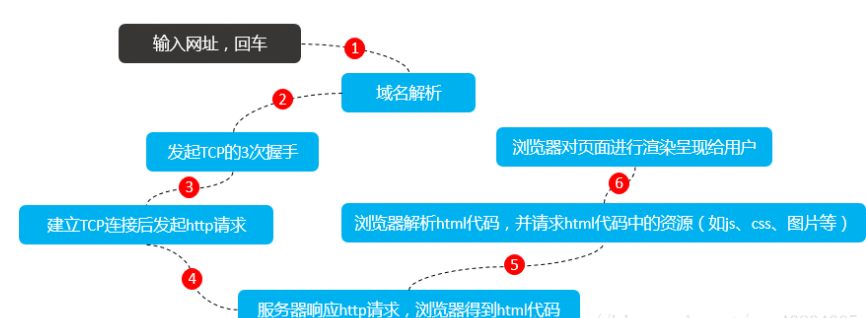
# 1.域名解析
首先浏览器会解析域名(准确的叫法应该是主机名)得到对应的IP地址,那怎么解析到对应的IP地址? ① 浏览器会首先搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存),看自身的缓存中是否有该域名对应的条目,而且没有过期,如果有且没有过期则解析到此结束; ② 如果浏览器自身的缓存里面没有找到对应的条目,那么浏览器会搜索操作系统自身的DNS缓存,如果找到且没有过期则停止搜索解析到此结束; ③ 如果在Windows系统的DNS缓存也没有找到,那么尝试读取hosts文件(位于C:\Windows\System32\drivers\etc),看看这里面有没有该域名对应的IP地址,如果有则解析成功; ④ 如果在hosts文件中也没有找到对应的条目,浏览器就会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器(一般是电信运营商提供的,也可以使用像Google提供的DNS服务器)发起域名解析请求(通过的是UDP协议向DNS的53端口发起请求,这个请求是递归的请求,也就是运营商的DNS服务器必须得提供给我们该域名的IP地址),运营商的DNS服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。如果没有找到对应的条目,则有运营商的DNS代我们的浏览器发起迭代DNS解析请求,它首先是会找根域的DNS的IP地址(这个DNS服务器都内置13台根域的DNS的IP地址),然后进一步请求; 正常情况下通过这四步基本就能解析域名获得IP了;
# 2.发起TCP三次握手
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024 < 端口 < 65535)向服务器的WEB程序的80端口发起TCP的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序,最终建立了TCP/IP的连接。
# 为什么HTTP协议要基于TCP来实现?
目前在Internet中所有的传输都是通过TCP/IP进行的,HTTP协议作为TCP/IP模型中应用层的协议也不例外,TCP是一个端到端的可靠的面向连接的协议,所以HTTP基于传输层TCP协议不用担心数据的传输的各种问题。
# 3.建立连接后发起HTTP请求
进过TCP3次握手之后,浏览器发起了http的请求
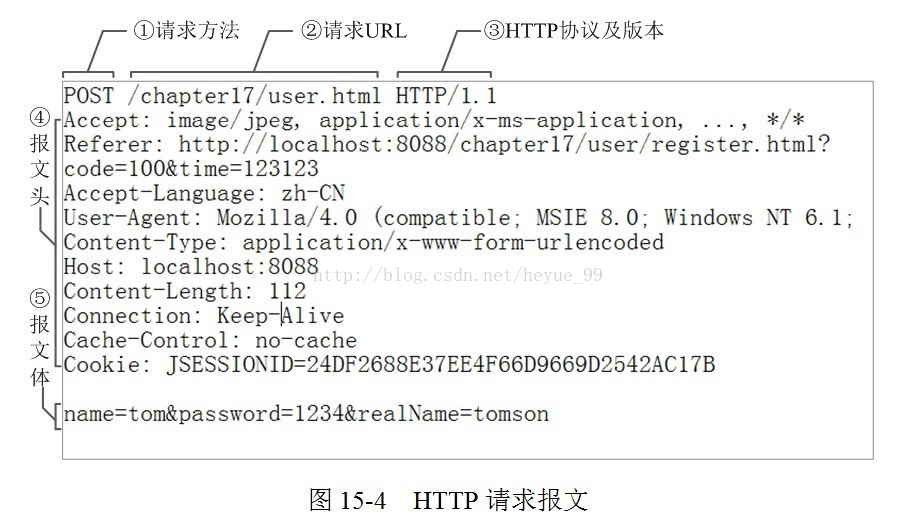
HTTP请求报文格式(HTTP请求报文由3部分组成(请求行+请求头+请求体))
# 请求行:
①是请求方法,GET和POST是最常见的HTTP方法,除此以外还包括DELETE、HEAD、OPTIONS、PUT、TRACE。 ②为请求对应的URL地址,它和报文头的Host属性组成完整的请求URL。 ③是协议名称及版本号。
# 请求头:
④是HTTP的报文头,报文头包含若干个属性,格式为“属性名:属性值”,服务端据此获取客户端的信息。 与缓存相关的规则信息,均包含在header中
# 请求体:
⑤是报文体,它将一个页面表单中的组件值通过param1=value1&m2=value2的键值对形式编码成一个格式化串,它承载多个请求参数的数据。不但报文体可以传递请求参数,请求URL也可以通过类似于“/chapter15/user.html?param1=value1&m2=value2”的方式传递请求参数。
# 什么是URL、URI、URN?
URI :Uniform Resource Identifier 统一资源标识符 URL:Uniform Resource Locator 统一资源定位符 URN: Uniform Resource Name 统一资源名称 URL和URN 都属于 URI
# 4.服务器响应HTTP请求,浏览器得到HTML
服务器端WEB程序接收到http请求以后,就开始处理该请求,处理之后就返回给浏览器html文件
# 5.浏览器解析HTML代码,并请求代码中的资源(如果js、css、图片等)
浏览器拿到html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里的顺序,但是由于每个资源大小不一样,而浏览器又多线程请求请求资源,所以请求成功显示的顺序并不一定是代码里面的顺序。 浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。
# 6.浏览器对页面进行渲染呈现给用户
浏览器利用自己内部的工作机制,把请求到的静态资源和html代码进行渲染,渲染之后呈现给用户。
# 7.关闭TCP连接
这一步不是所有的网页都会这么做,例如网页版微信就没有关闭 TCP 连接,因为微信上别人可以随时发消息给你,实际上别人先把消息发送到了微信服务器,微信服务器再通过 TCP 链接,把消息推送到你的屏幕上。
试想一下,如果网页版微信关闭了 TCP 连接会怎样?
结果是:你不刷新网页,就永远收不到消息了。同时,如果你频繁的发消息给别人,那么就在频繁的创建连接,关闭连接,这是很消耗资源的。所以微信就干脆不关闭 TCP 连接,这样微信服务器就可以给我们的浏览器发消息。
一次Http请求报文头部信息,其中 Connection: keep-alive 意味着这次请求结束后不会关闭 TCP 连接。
当然不是所有的 HTTP 请求都没有关闭连接,例如一篇博文,浏览器收到数据显示就可以了,没有那么多动态数据,我看完就关了,这时就应该关闭 TCP 连接,当然这还是取决于请求的服务器。说了这么多,还没说关闭连接。
关闭 TCP 连接专业点说叫做“四次挥手”,与 TCP 建立连接的“三次握手”相对应。
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个 FIN 来终止这个方向的连接。收到一个 FIN 只意味着这一方向上没有数据流动,一个TCP连接在收到一个 FIN 后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
# HTTPS
# HTTPS的工作原理
客户端的浏览器 (opens new window)向服务器发送请求,并传送客户端SSL 协议的版本号 (opens new window),加密算法的种类,产生的随机数,以及其他服务器和客户端之间通讯所需要的各种信息。
服务器向客户端传送SSL 协议的版本号,加密算法的种类,随机数以及其他相关信息,同时服务器还将向客户端传送自己的证书。
客户端利用服务器传过来的信息验证服务器的合法性,服务器的合法性包括:证书是否过期,发行服务器证书 (opens new window)的CA 是否可靠,发行者证书的公钥能否正确解开服务器证书的“发行者的数字签名”,服务器证书上的域名 (opens new window)是否和服务器的实际域名相匹配。如果合法性验证没有通过,通讯将断开;如果合法性验证通过,将继续进行第四步。
用户端随机产生一个用于通讯的“对称密码”,然后用服务器的公钥(服务器的公钥从步骤②中的服务器的证书中获得)对其加密,然后将加密后的“预主密码”传给服务器。
如果服务器要求客户的身份认证(在握手过程中为可选),用户可以建立一个随机数然后对其进行数据签名,将这个含有签名的随机数和客户自己的证书以及加密过的“预主密码”一起传给服务器。
如果服务器要求客户的身份认证,服务器必须检验客户证书和签名随机数的合法性,具体的合法性验证过程包括:客户的证书使用日期是否有效,为客户提供证书的CA 是否可靠,发行CA 的公钥能否正确解开客户证书的发行CA 的数字签名,检查客户的证书是否在证书废止列表(CRL)中。检验如果没有通过,通讯立刻中断;如果验证通过,服务器将用自己的私钥解开加密的“预主密码”,然后执行一系列步骤来产生主通讯密码 (opens new window)(客户端也将通过同样的方法产生相同的主通讯密码)。
服务器和客户端用相同的主密码即“通话密码”,一个对称密钥 (opens new window)用于SSL 协议的安全数据通讯 (opens new window)的加解密通讯 (opens new window)。同时在SSL 通讯过程中还要完成数据通讯的完整性,防止数据通讯中的任何变化。
客户端 (opens new window)向服务器 (opens new window)端发出信息,指明后面的数据通讯将使用的步骤⑦中的主密码为对称密钥 (opens new window),同时通知服务器客户端的握手过程结束。
服务器向客户端发出信息,指明后面的数据通讯将使用的步骤⑦中的主密码为对称密钥,同时通知客户端服务器端的握手过程结束。
SSL 的握手部分结束,SSL 安全通道的数据通讯开始,客户和服务器开始使用相同的对称密钥进行数据通讯,同时进行通讯完整性的检验。

