 一些面经里的面试题
一些面经里的面试题
Table of Contents generated with DocToc (opens new window)
# 美团
# 八股
# Java基础
# 红黑树了解吗,它的三大特性?
# 抽象类和接口的区别
相同点:
- 都不能被实例化
- 都能包含抽象方法
- 用于描述系统提供的服务,不必提供具体实现
对比项目 抽象类 接口 方法 加abstract的为抽象方法,方法可以用public、protected、default这些访问控制符修饰。子类继承此抽象类时,需重写这些抽象方法 接口的所有未加static或default修饰的方法(jdk8+)都是public abstract方法(可定义时可以不写public abstract,但不能用其他关键字修饰),实现接口时,必须实现所有的这些方法 属性 和普通类的属性一样 接口中的变量都是static final(定义时可省略)修饰的静态变量 构造方法 有构造方法 没有构造方法 继承/实现 抽象类无法不能被实例化,只能被继承。和普通类的继承机制一样 接口与接口之间不能implements,可以继承 速度 比接口速度快 因为接口需要时间去找实现类 添加新方法 抽象类中添加,如果提供了默认实现,不需要修改现在的代码 接口中添加 非static/default修饰的方法(jdk8+),需要修改代码(实现方法)设计层面 抽象类是对一种事物的抽象,即对类抽象,包括属性、行为接口是只对行为的抽象 使用原则 模板式设计模式-->在使用时可以将部分逻辑以具体方法和具体构造函数形式实现,然后声明一些抽象方法来迫使子类实现剩余的逻辑,这个抽象类父类就相当于一个模板,具有这些类的相同的一些功能,并给子类提供了扩展方法,如果子类需要实现不同的功能,实现父类的抽象方法即可 定义一种规范、标准 # Java面向对象的特点。多态是啥?
- 特点:封装、继承、多态
- 多态:
实现关系下的多态,接口的引用类型变量指向了接口实现类的对象继承关系下的多态,父类的引用类型变量指向了子类的对象- 多态情况下,子父类存在同名的成员变量时,访问的是父类的成员变量
- 多态情况下,子父类存在同名的非静态的成员函数时,访问的是子类的成员函数
- 多态情况下,子父类存在同名的静态的成员函数时,访问的是父类的成员函数
- 多态情况下,父类不能访问子类特有的成员
# 重载和重写的区别
重载:
方法名相同,参数肯定不同,返回值可以相同也可以不同重写:方法体不同,其他完全相同
# java中常见的集合有哪些,分别介绍一下?
List:ArrayList、LinkedList、Vector、CopyOnWriteList
Map:HashMap、LinkedHashMap、TreeMap
Set:HashSet、LinkedHashSet、TreeSet
# ArrayList与LinkedList区别
- ArrayList底层基于数组,LinkedList基于双向链表
# ArrayList扩容机制
jdk7new实例时初始化数组大小为10,jdk8在add时才初始化数组长度为10,如果add后个数大于数组长度,扩容为原来的1.5倍,然后copy元素过去
# HashMap和CurrentHashMap底层原理?AVL和红黑树 (opens new window)的区别?
# ConcurrentHashMap的底层数据结构?
jdk7:Entry数组+链表:分为多个Segment,每个Segment持有多个Entry(一个Entry数组),在多线程操作时,只锁当前操作的Segment,其他的Segment不受影响
jdk8:Node数组+链表+红黑树:多线程环境下,当hash找到的Node数组下标位置为空时,casTabAt中使用compareAndSwapObject保证插入的线程安全;当产生hash冲突时,使用synchronized锁单个Node结点插入或覆盖值
# String、StringBuilder和StringBuffer
- String
类、类中的字段都是final修饰的,字段私有且不提供能修改内部状态的方法- String底层是一个final修饰char数组常量,意味着初次赋值后不可以再改变(不可变性)
- 重新赋值会指定一个新的内存区域赋值,不会使用原有的value数组赋值
- String str = "xxx"的方式,实际只创建了一个对象,存在于字符串常量池中
- new String("xxx")的时候会产生两个对象,new的对象存在于堆中,"xxx"存在于字符串常量池中
- StringBuilder
- StringBuilder底层是非final修饰的char数组,是可变的,提供很多对字符串增删改的操作方法,效率高,但是线程不安全
- StringBuffer
- StringBuffer和StringBuilder实现相差不大,但StringBuffer操作方法都加了synchronized修饰,是线程安全的
# 为什么StringBuffer线程安全
方法synchronized修饰
# 为什么要有线程安全和线程不安全两种,都设成线程安全不好么
有的应用几乎都在单线程环境下,就只使用StringBuilder,提高效率
# 你觉得为什么java把String设计为不可变的
作者James Gosling说主要是从缓存、安全性、线程安全和性能等角度出发的。
缓存:字符串是使用最广泛的数据结构。大量的字符串的创建是非常耗费资源的,所以,Java提供了对字符串的缓存功能,可以大大地节省堆空间。如果是可变的,String s1 = "abc",s2=s1,这时如果我们改变了s1的值,s2的值也被改变了,这显然不是我们想看到的
安全性:字符串在Java应用程序中广泛用于存储敏感信息,如用户名、密码、连接url、网络连接等。JVM类加载器在加载类的时也广泛地使用它。
因此,保护String类对于提升整个应用程序的安全性至关重要。当我们在程序中传递一个字符串的时候,如果这个字符串的内容是不可变的,那么我们就可以相信这个字符串中的内容。但是,如果是可变的,那么这个字符串内容就可能随时都被修改。那么这个字符串内容就完全可信了。这样整个系统就没有安全性可言了。
线程安全:不可变会自动使字符串成为线程安全的,因为当从多个线程访问它们时,它们不会被更改。
hashcode缓存
# 哈希冲突是什么情况(用HashMap来举例)
调hash()方法,两个key得到的hash值是一样的,但是HashMap底层数组的一个位置只能留一个(如果equals也相等)
如果解决hash冲突:
- 开放地址法:
- 线性探测:找当前冲突位置下标+1的位置是否为空,不为空继续找,直到把数组循环一遍,只要表未填满,总能放下,但缺点是会产生聚集问题,多个hash一样的都聚集在一起,长度越长,后续的相同hash探测的时间会越来越长
- 平方探测:依次向前后查找:1^2,-1^2(向左),2^2,-2^2....,更灵活
- 再散列法:
- 用另一个不同计算方式的hash函数对这个key重新进行hash,探测的时候用新的hash值去探测,由于hash函数不同,碰撞的概率会很低,避免二次聚集,但需付出计算另一个hash函数的代价
- 拉链法(链地址法),参考HashMap
- 开放地址法:
# 位图了解过么?
# Java集合框架中有哪些接口,Map有哪几种
# HashMap的初始化、扩容和树化
- 初始化:
- jdk7:new的时候,创建默认容量为16的Entry数组,负载因子0.75
- jdk8:new的时候不创建,第一次put的时候调用resize()创建默认长度16的Node数组,负载因子一样
- 扩容:
- jdk7:存入之前判断是否需要扩容:大于阈值,且发生hash冲突
- jdk8:存入之后判断扩容: 不hash冲突且大于阈值,直接扩容,hash冲突,看链表长度和数组长度,链表小于8,存进去,大于8,如果数组小于64,扩容,大于64,转红黑树
- 初始化:
# HashMap容量为什么是2的幂次
# HashMap容量、阈值、负载因子之间的关系
容量是底层数组的长度,阈值是数组是否需要扩容的界限值,阈值=容量*负载因子
# HashMap负载因子为什么是0.75
泊松分布
# HashMap和Hashtable继承的是哪个类
# 为什么不使用Hashtable
线程安全,效率低
# 介绍一下ConcurrentHashMap
# HashMap是有序的吗,TreeMap呢
无序;对于Integer、String等实现了Comparable接口的类,是可以自动排序的(升序),自定义类需要类实现Comparable接口,或者传入一个Compartor接口的实现类作为构造函数参数来实现排序
# final关键字
- final修饰类中的属性或者变量:不可变性->不能对变量进行重新赋值,即赋值后不能更改
- final修饰类中的方法:该方法可以被继承,但不能被重写->其实也是符合不可变性
- final修饰类:该被修饰的类不可以被其他类继承
# 设计模式
# 了解设计模式吗,举个Jdk中设计模式的例子(AQS模板模式)
# 装饰器模式了解吗(不会),InputStream原理(不会)
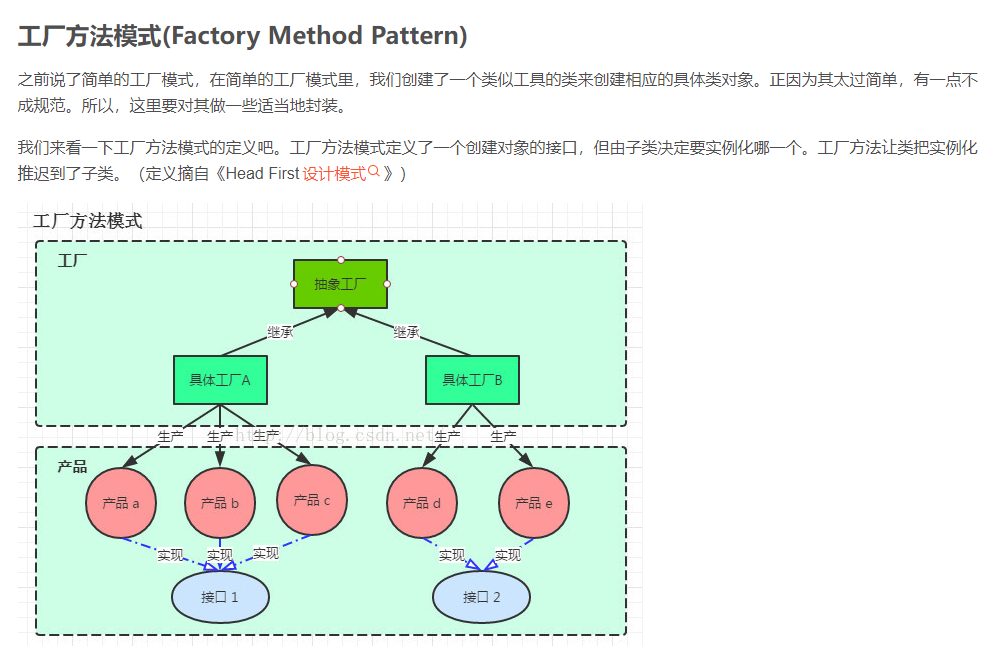
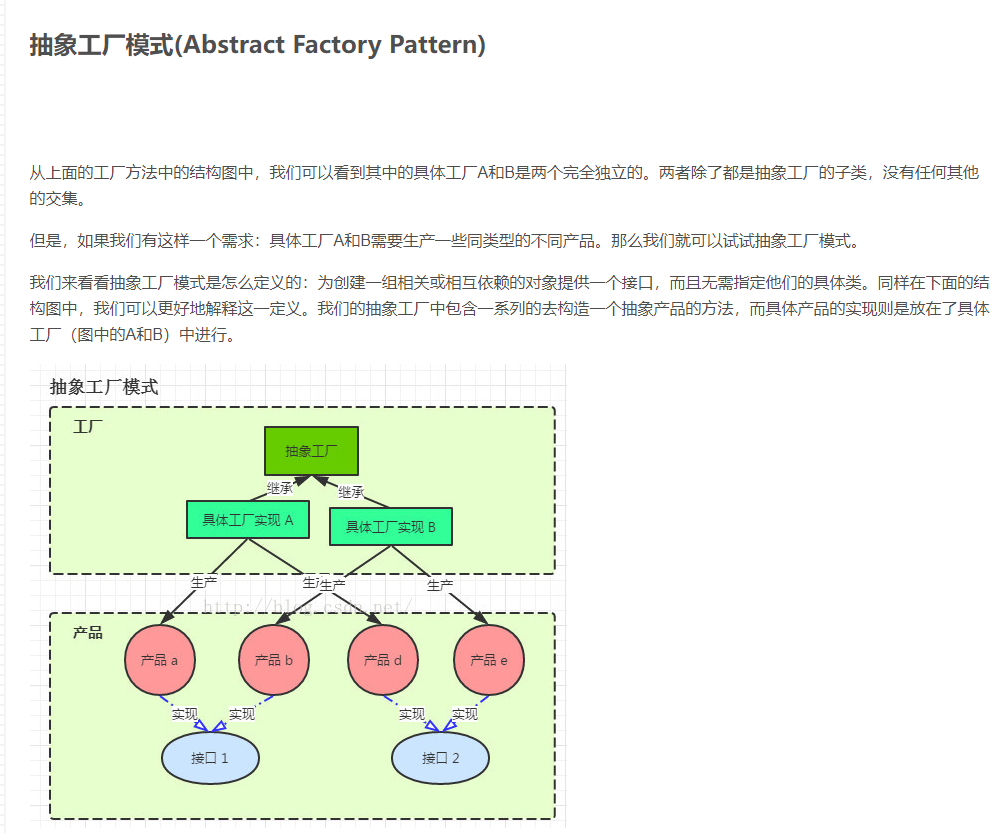
# 谈谈你知道的设计模式、再详细介绍一下你对简单工厂、工厂、抽象工厂的看法
简单/静态工厂模式:简单根据类名等直接返回new的对象
工厂方法模式:
一个动物工厂interface,其包含一个createAnimal方法,可以创建任何宠物;
其他的猫工厂、狗工厂实现这个interface,方法返回具体猫、狗;
当想要狗的时候:
// 去找狗工厂拿一只狗过来 AnimalFactory factory = new DogFactory(); Animal dog = factory .createAnimal();
要猫同理。
即:一个新对象增加,只需要增加一个具体的类和具体的工厂类即可
抽象工厂模式
# 设计模式的原则了解哪些
# 多线程
# 创建线程有哪些方式
# 创建线程池的方法,线程池的参数,饱和策略拒绝会抛出什么异常?
# 异常有哪些,error和运行时异常的区别?解释一下FileNotFoundException
# 现场设计一个死锁的场景
# 进程 线程 协程区别?进程通信?线程池参数使用?知道 newFixedThreadPool吧?说说特点和它的阻塞队列?它会OOM为什么?
# java中用来线程同步的锁有哪些?
- Synchronized
- ReentrantLock
- ReentrantReadWriteLock
# synchronized 和 Lock 有什么区别?
相同:都可以重入
不同:
- synchronized会自动释放锁,Lock需要手动释放
- synchronized是关键字,Lock是接口(类)
- synchronized不可以判断获取锁的状态,Lock可以判断是否获取到了锁
- 当线程2需要的锁被线程1获取时,使用Lock的tryLock()和tryLock(long time,TimeUnit timeUnit)可以尝试获取锁,不会导致线程2一直等待
- synchronized可以锁方法或代码块,而Lock只能锁代码块
# volatile了解吗?和synchronized的区别是什么?ReentrantLock和synchronized的区别是啥?
volatile是jvm提供的轻量级的同步机制
volatile并不是锁,只是让被它修饰的变量在修改时,禁止指令重排,在修改后对其他线程都可见(可见性),但它并不保证原子性
# 线程池核心参数与工作流程(原理)
# n个线程阻塞,等待某个事件发生后被唤醒,怎么实现
# CyclicBarrier的实现原理,自己做怎么实现
# CyclicBarrier和CountDownLatch的区别
# AQS看过吗? 抽象的队列式同步器
# AQS使用了什么设计模式?(是模版方法模式的经典应用)
# ThreadLocal为什么会内存泄漏?如何避免?ThreadLocal的优化了解过吗?
# 核心线程什么时候创建的?(核心线程默认不创建,当提交任务到线程池中时才创建,有参数可以预热)
# volatile具体的实现?有序性和可见性?
# 为什么volatile不满足原子性?
# 进程间的通信方式 (只回答了四种匿名管道,有名管道,消息队列,信号量)
# JVM
# JVM的双亲委派模型介绍一下
# 类加载的过程?双亲委派机制了解吗?有什么好处?
# jvm内存结构是啥样的?
# JVM内存区域
# 堆分成两代你知道么?为什么要分代,不整合在一起
# G1了解过么(这个我了解的其实不太透彻,就把我知道的说了说,现在想想他似乎是接着上一个问题问的,因为G1就是分成了很多块)
# 一个对象如何会被GC
# 强引用、软引用、弱引用、虚引用的区别和使用场景
# 强引用能被GC吗,强引用设置为null会怎么样(不会)
# JVM内存模型了解过吗,为什么你说本地方法栈执行方法的时候程序计数器是空?
# 你参与过JVM调优吗
# MySQL
# 用过哪些数据库?MySQL和其他的数据库相比有什么优点?(事务支持,ACID,存储引擎,三大日志,索引,锁机制,MVCC)
# MySQL中对SQL语句的优化了解过么?
# MySQL的隔离机制,默认隔离机制,RR的脏读幻读,解决幻读的方法
# MySQL中的锁定读,间隙锁,间隙锁是行锁还是表锁还是页锁?
# 如果数据库中锁定读的并发比较高,有什么办法解决?
# 索引(聚簇索引、非聚簇索引)以及底层数据结构
# 怎样处理高并发场景?(通过锁解决 写+写并发,通过无锁化MVCC解决 读+写 并发)
# 利用索引查询的原理,覆盖索引,联合查询,为什么使用B+🌲结构(其实这些问题本质上就是为了减少磁盘 I/O 的次数,要深刻理解)
# MySQL 有缓存吗,怎么缓存查询的?
# 索引类型,InnoDB使用的索引 为什么不使用别的索引类型?
# 数据库的索引结构?为什么用B+树?什么是最左前缀匹配原则?
# 了解DNS域名解析吗?简单叙述一下过程
# 慢sql该怎么分析?
# 数据库的四大隔离级别是啥?默认隔离级别是哪个?
# mysql中为什么主要使用innodb
# select * from table limit 800000,10; 很慢如何优化
# 索引结构 B+树为什么是3层不是2层5层8层?(答层数高了IO次数会变多?) 最左匹配 写SQL查询表中各科成绩最高分
# binlog 和 redolog 的区别
# 回表查询了解过吗?
# 有没有听过索引下推
# 一般怎么优化sql调优
# 实际遇到中的问题:业务方传递的参数导致对需要几亿条数据全表查询,猜一下会发生什么?(发生OOM)如何解决?(使用参数校验与设置限制解决)
# MySQL InnoDB引擎的索引结构,联合索引怎么建的
# 提到了MVCC,问了下MVCC的实现
# Redis
# Redis的数据结构,对应的底层数据结构都有什么?项目里用的什么数据结构,key是什么
# 详细介绍一下 string 类型的底层数据结构(简单动态字符串 simple dynamic string)
# Redis实现分布式锁的方法
# Redis主从一致性的实现
# 布隆过滤器了解吗?
布隆过滤器是基于
bitmap和若干个hash算法实现的。如下图所示: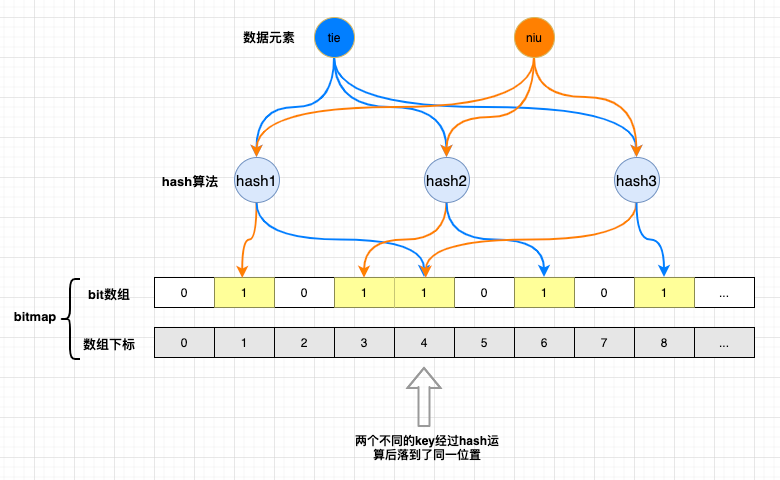
1.元素
tie经过hash1,hash2,hash3运算出对应的三个值落到了数组下标为4,6,8的位置上,并将其位置的默认值0,修改成1。2.元素
niu同理落到了数组下标为1,3,4的位置上,并将其位置的默认值0,修改成1。此时
bitmap中已经存储了tie,niu数据元素。当请求想通过布隆过滤器判断
tie元素在程序中是否存在时,通过hash运算结果到数组对应下标位置上发现值已经都被置为1,此时返回true。一定不在集合中:
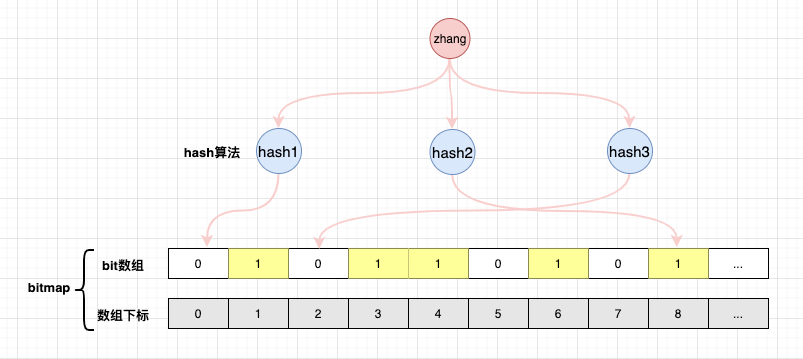
如图所示:
元素
zhang通过布隆过滤器判断时,下标0,2都为0,则直接返回false。也就是当判断不在
bitmap中的元素时,经过hash运算得到的结果在bitmap中只要有一个为0,则该数据一定不存在。可能在集合中:
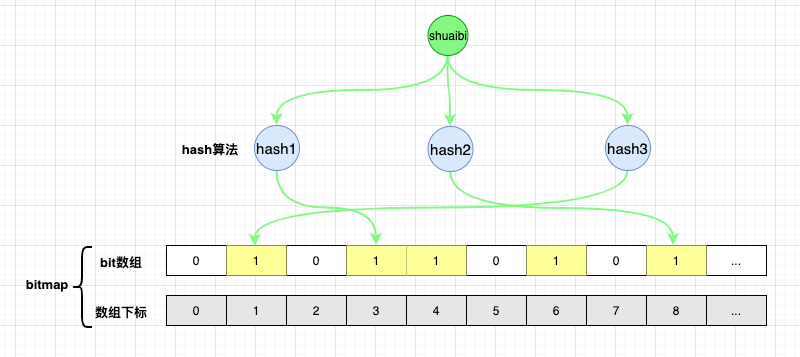
如图所示:
元素
shuaibi通过布隆过滤器判断时,hash运算的结果落到了下标1,3,8上,此时对应下标位置的值都为1,则直接返回true。这下就尴尬了,因为实际程序中并没有数据
shuaibi,但布隆过滤器返回的结果显示有这个元素。这就是布隆过滤器的缺点,存在误判情况。删除困难:
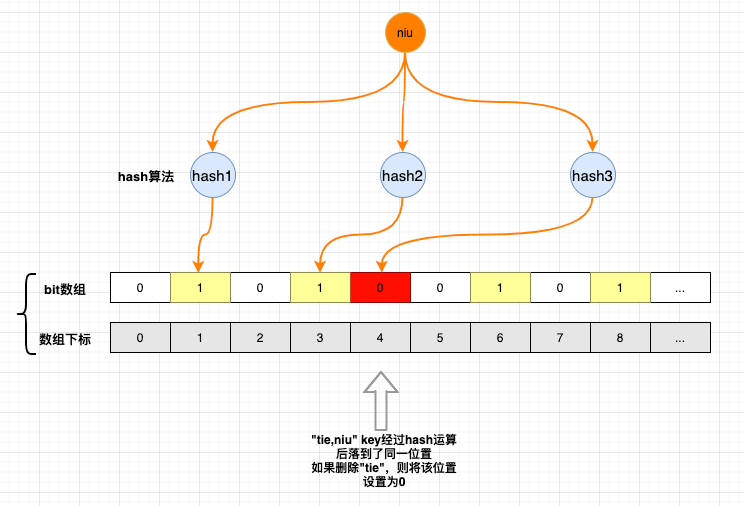
如果删除了“tie”元素,
4号位被置为0,则会影响niu元素的判断,因为4号位为0,进行数据校验时返回0,则会认为程序中没有niu元素# Redis缓存会出现什么问题,讲一下缓存穿透、缓存雪崩、缓存击穿
一、缓存穿透
缓存中不存在对应的key,大量请求涌入数据库查询,而数据库也不存在对应的数据,将数据库冲垮
解决办法
接口请求参数的校验。对请求的接口进行鉴权,数据合法性的校验等;比如查询的userId不能是负值或者包含非法字符等
缓存空对象
当数据库返回null查询不到的时候,缓存层将null缓存起来,并设置一个过期时间(较短),让以后一定时间内相同条件的查询都从缓存层返回null
但是也有以下问题:
第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重 ),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为 5 分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
对于第一点,建议空值放在另外的缓存空间中,不宜与正常值共用空间,否则当空间不足时,缓存系统的LRU算法可能会先剔除正常值,再剔除空值——这个漏洞可能会受到攻击。
对于第二点,如果是Redis缓存,更新数据后直接在Redis中清除即可;如果是本地缓存,就需要用消息来通知其他机器清除各自的本地缓存。
使用布隆过滤器
使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库
二、缓存击穿
某个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,导致数据库存在被打挂的风险
解决办法
- 加互斥锁。当热点key过期后,大量的请求涌入时,只有第一个请求能获取锁并阻塞,此时该请求查询数据库,并将查询结果写入redis后释放锁。后续的请求直接走缓存
- 设置缓存不过期或者后台有线程一直给热点数据续期
三、缓存雪崩
大量的热点数据过期时间相同,导致数据在同一时刻集体失效。造成瞬时数据库请求量大、压力骤增,引起雪崩,导致数据库存在被打挂的风险
解决办法
- 将热点数据的过期时间打散。给热点数据设置过期时间时加个随机值。
- 加互斥锁。当热点key过期后,大量的请求涌入时,只有第一个请求能获取锁并阻塞,此时该请求查询数据库,并将查询结果写入redis后释放锁。后续的请求直接走缓存
- 设置缓存不过期或者后台有线程一直给热点数据续期
# 你理解的Redis会在什么场景下用到
# 网络TCP(HTTP(s))
# get和post请求的区别
- 携带请求数据的方式:get在url后,post在请求的body里面
- 携带数据长度限制:http并没有对数据长度进行限制,有限制是特定浏览器,会把get(url)限制长度,而post因为在请求body中,长度不受限
- 安全性:通过get(url),账号密码等会明文显示在url地址栏造成安全问题
# session和cookie的区别
- 存储位置:session储存在服务端,cookie储存在客户端
- 生命周期:session在浏览器会话关闭,或者服务端重启后都会消失,而cookie是根据访问的站点设置的时间来的
- 安全性:session由于储存在服务端,攻击人员较难获取到session信息来伪造身份;而由于cookie储存在客户端,可以较容易获取到,被用于伪造身份
- 储存的信息大小:单个cookie的储存大小不能超过4kb,并且很多站点会限制cookie保存的个数,session基本没有什么限制
- 占用:session由于需要存放到服务端,如果数量多了以后,会较大占用服务端资源;
- session的运行依赖于sessionID,sessionID又存在于cookie中;如果禁用了cookie,可以通过url传递jsessionId
# 什么是http幂等性
- 幂等是一个数学概念:1次变换和N次变换的结果是一样的
- http的幂等:我理解的是同样的一次请求,请求一次和请求多次,所得到的结果是一样的
# 浏览器中输入:“ www.meituan.com (opens new window)”之后都发生了什么
# 三次握手四次挥手
三次握手:
- 客户端向服务器发送一个tcp连接请求报文,附上自己的seq,发送后,客户端处于SYN_SENT已发送状态
- 服务器收到请求报文,将客户端的seq+1作为ack,并附上自己的seq发送给客户端,表示自己已经收到了连接请求,进入SYN_RCVD已接收状态,并把此时的连接加入到半连接队列中
- 客户端收到SYN报文后,发送ACK报文,将服务器的seq+1作为ack发送给服务端,表示已经收到了服务端的SYN报文,然后客户端处于ESTABLISHED 状态,服务器收到该ACK报文后,也进入ESTABLISHED,连接就建立起来了,服务端并将此连接加入到全连接队列中
# https 的原理以及建立完整连接的全过程
加密。服务端将证书发给客户端,客户端验证证书的有效性,如果有效,就生成一个随机值(私钥)并用证书中的公钥进行加密,然后发送给服务端,服务端收到这个信息以后,用证书的私钥将信息解密,得到客户端发送的随机值(私钥),两端就可以通过这个随机值(私钥)进行通信。服务端将私钥加密后的消息传送给客户端,客户端用私钥解密获取。
# CA 证书的内容有什么?
- Issuer--证书的颁发机构
- Valid from,Valid to--证书的有效期
- Public key--公钥
- Subject--主题:证书是颁发给了谁,一般是个人或公司名称或机构名称或公司网站的网址
- Signature algorithm--数字证书的数字签名所使用的加密算法,根据这个算法可以对指纹解密。指纹加密的结果就是数字签名。
# OSI七层网络模型
自底向上:
- 物理层
- 数据链路层
- 网络层
- 传输层
- 会话层
- 表示层
- 应用层
# TCP/IP的五层网络模型
自底向上:
物理层
主要协议:由顶层网络定义的协议
数据链路层
主要协议同上
网络层
主要协议:ICMP、IGMP、IP、ARP、RARP
传输层
主要协议:TCP、UDP
应用层
主要协议:HTTP、FTP、TFTP、SMTP、SNMP、DNS
# http、tcp 分别在七层网络中的哪层
http在应用层,tcp在传输层
# 哪些应用层协议使用 TCP,哪些用 UDP
TCP:
协议 全称 默认端口 HTTP HyperText Transfer Protocol(超文本传输协议) 80 FTP File Transfer Protocol (文件传输协议) 20用于传输数据,21用于传输控制信息 SMTP Simple Mail Transfer Protocol (简单邮件传输协议) 25 TELNET Teletype over the Network (网络电传,用于远程登录) 23 SSH Secure Shell 22 UDP
协议 全称 默认端口 DNS Domain Name Service (域名服务) 53 TFTP Trivial File Transfer Protocol (简单文件传输协议) 69 SNMP Simple Network Management Protocol (简单网络管理协议) 通过UDP端口161接收,只有Trap信息采用UDP端口162。 NTP Network Time Protocol (网络时间协议) 123 # 为什么 tcp 是三次握手,两次不行吗?
两次就是不行原因
防止已失效的请求报文段突然又重新到达服务器,浪费服务器资源。
客户端发送的第一个请求报文段在某一个网络节点长时间滞留,并没有丢失,以致于到上一个连接释放后才到达服务器,服务器会误认为这是一个新的连接请求,如果是两次握手,服务器收到这个报文后,会向客户端发送确认报文,并进入已连接状态,但是因为这个报文是失效了的,客户端并不理睬这个确认报文,也不会向服务器发送数据,而服务器连接是已经建立好了,一直在等待客户端发送数据,这样就白白浪费了服务器的资源
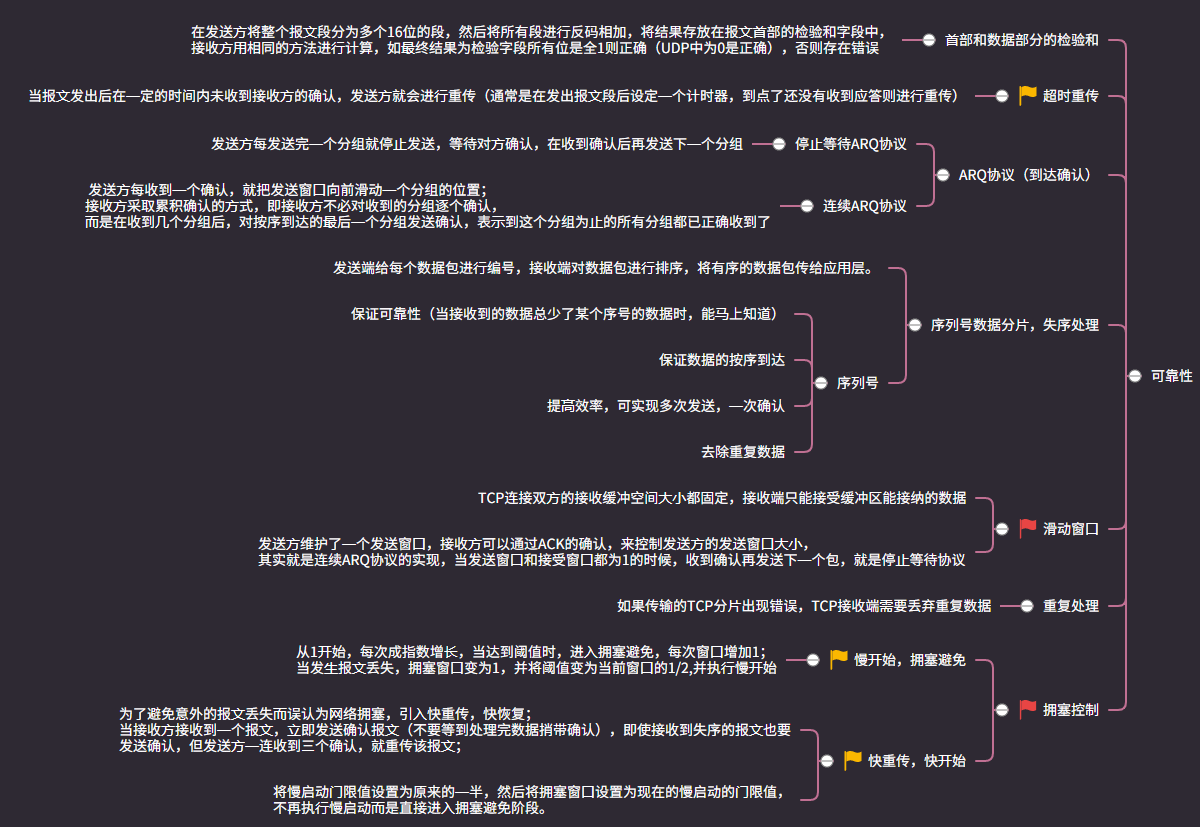
# TCP与UDP的区别?为什么TCP是可靠的?TCP保证可靠传输的机制?
区别
- TCP是面向字节流的传输;UDP是面向用户数据报(应用报文)的传输
- TCP是面向连接的,通过三次挥手建立连接,传输数据,四次挥手释放连接;UDP是无连接的,即发送数据之前不需要建立连接
- TCP是可靠的通信方式,通过超时重传、数据校验等方式保证数据无差错、不丢失、不重复,且按序到达,UDP是不可靠的,即发送的数据不保证有序、重复、丢失
- TCP是一对一的连接,而UDP可以一对一、一对多、多对多
TCP可靠原因
# TCP粘包、拆包了解吗?解释一下
粘包、拆包的概念
发送方发送了D1、D2两个包,由于接收端一次读取到的字节数是不能确定的,所以有以下几种情况
- 接收端分两次分别读到了D1,D2两个独立的包,没有粘包和拆包
- 接收端一次读到了两个包,D1D2粘合在一起,成为粘包
- 接收端分两次读到了D1、D2,第一次读到D1的全部和D2的部分,第二次读到D2的剩下部分,称为拆包
- 接收端分两次读到了D1、D2,第一次读到D1的部分,第二次读到D1的剩下部分和D2的全部,也称为拆包
特别要注意的是,如果TCP的接受滑窗非常小,而数据包D1和D2比较大,很有可能会发生第五种情况,即服务端分多次才能将D1和D2包完全接受,期间发生多次拆包。
粘包、拆包产生的原因
滑动窗口
粘包:假设发送方一个完整的报文的大小是256字节,当接收方由于数据处理不及时,这256个字节的数据都会被缓存到SO_RCVBUF(接收缓存区)中。如果接收方的接收缓存区中缓存了多个报文,那么对于接收方而言,就产生了粘包
拆包:假设接收方的窗口大小是128字节,意味着发送方最多还可以发送128字节的数据,而由于发送方的数据大小是256字节,所以发送方只能先发送前128个字节的数据,等收到接收方确认后才能发送剩余的字节,这就造成的拆包
MSS和MTU分片
Nagle算法
粘包、拆包的解决思路
一般是通过定义应用的协议来解决。协议的作用就是定义传输和解析数据的格式,这样在接收数据时,如果粘包了,可以根据定义的数据格式对大包进行拆分为各个单独的包;如果拆包了,就等待数据可以构成一个完整的包来处理。
定长协议:规定指定的字节数量表示一个有效报文。假设我们规定每3个字节,表示一个有效报文,如果我们分4次总共发送以下9个字节:
+---+----+------+----+ | A | BC | DEFG | HI | +---+----+------+----+1
2
3那么根据协议,我们可以判断出来,这里包含了3个有效的请求报文
+-----+-----+-----+ | ABC | DEF | GHI | +-----+-----+-----+1
2
3特殊字符分隔符协议:在包尾部增加回车或者空格符等特殊字符进行报文分割
例如,按行解析,遇到字符\n、\r\n的时候,就认为是一个完整的数据包。对于以下二进制字节流:
+--------------+ | ABC\nDEF\r\n | +--------------+1
2
3那么根据协议,我们可以判断出来,这里包含了2个有效的请求报文
+-----+-----+ | ABC | DEF | +-----+-----+1
2
3长度编码:包分为header和body,header中用一个int型数据(4字节),表示body的长度。在解析时,先读取Length,其值为实际body内容(Content)占用的字节数,之后必须读取到这么多字节的内容,才认为是一个完整的数据报文
header body +--------+----------+ | Length | Content | +--------+----------+1
2
3
4
# 拥塞处理怎么处理的
四种算法
- 慢开始
- 拥塞避免
- 快重传
- 快恢复
# 为什么说 TCP 面向连接而 UDP 不面向连接
# OSI7层网络模型,及其每一层的协议
# Spring
# 如何进行参数校验,什么是水平越权
# 什么是AOP,举个例子,拦截器讲一下
# 读过Spring的源码吗?AOP的原理?
# Spring Bean的生命周期
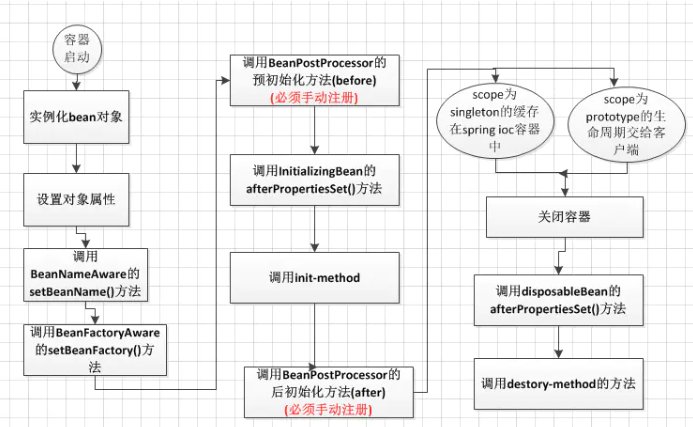
各个阶段
- 创建实例阶段->createBeanInstance():
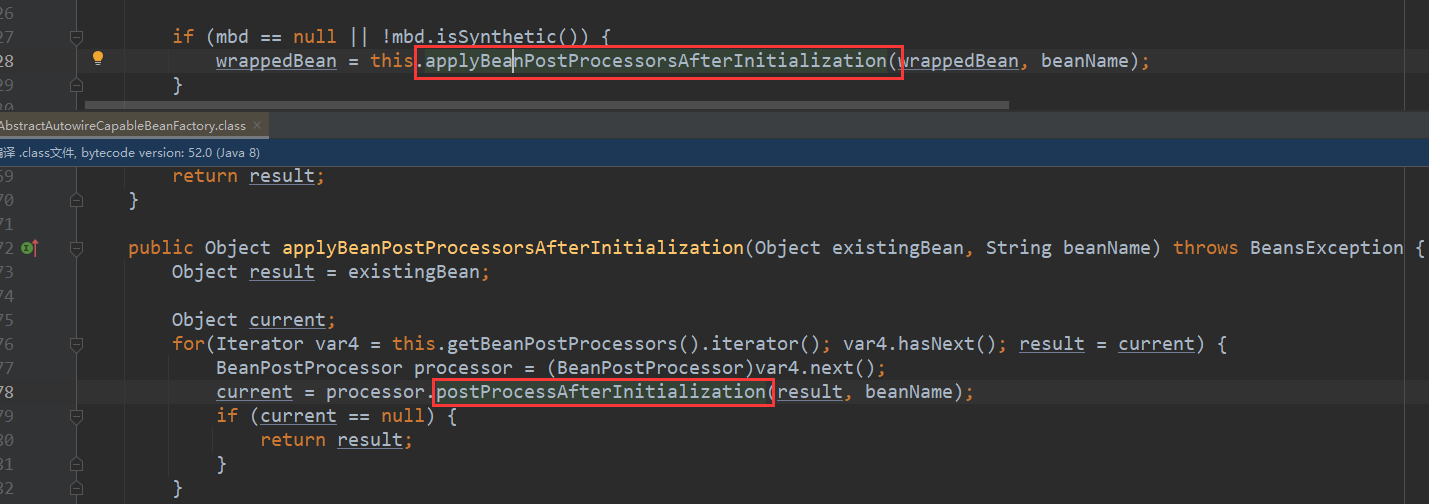
对于实现了InstantiationAwareBeanPostProcessor接口的Bean,在实例化之前会调用它实现的postProcessBeforeInstantiation方法,这个方法里面会判断当前的Bean是否是指定了代理类TargetSource,如果指定了,就直接用AbstractAutoProxyCreator类对其进行实例化,然后返回,到这里Bean已经算是实例化并初始化好了,所以执行postProcessAfterInitialization对初始化后的Bean进行处理
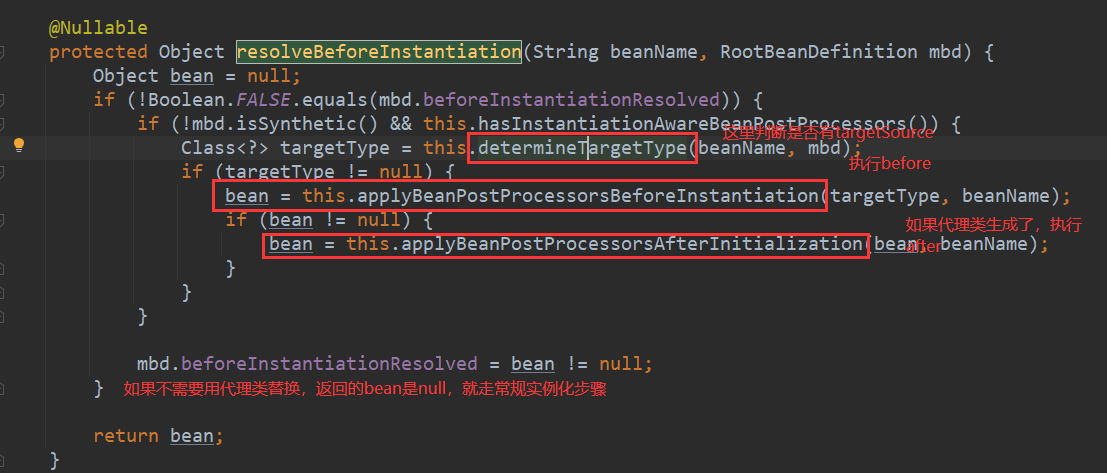
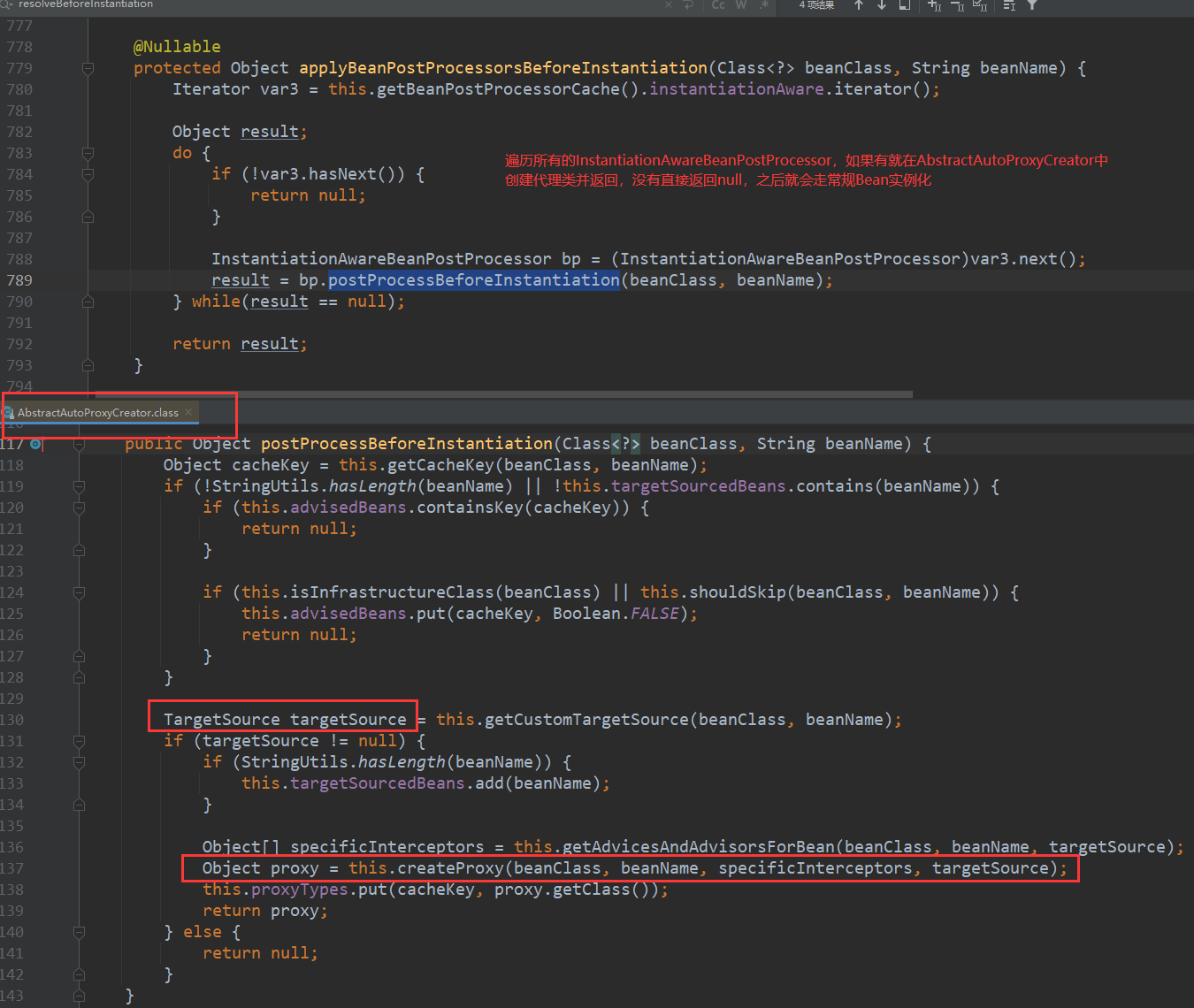
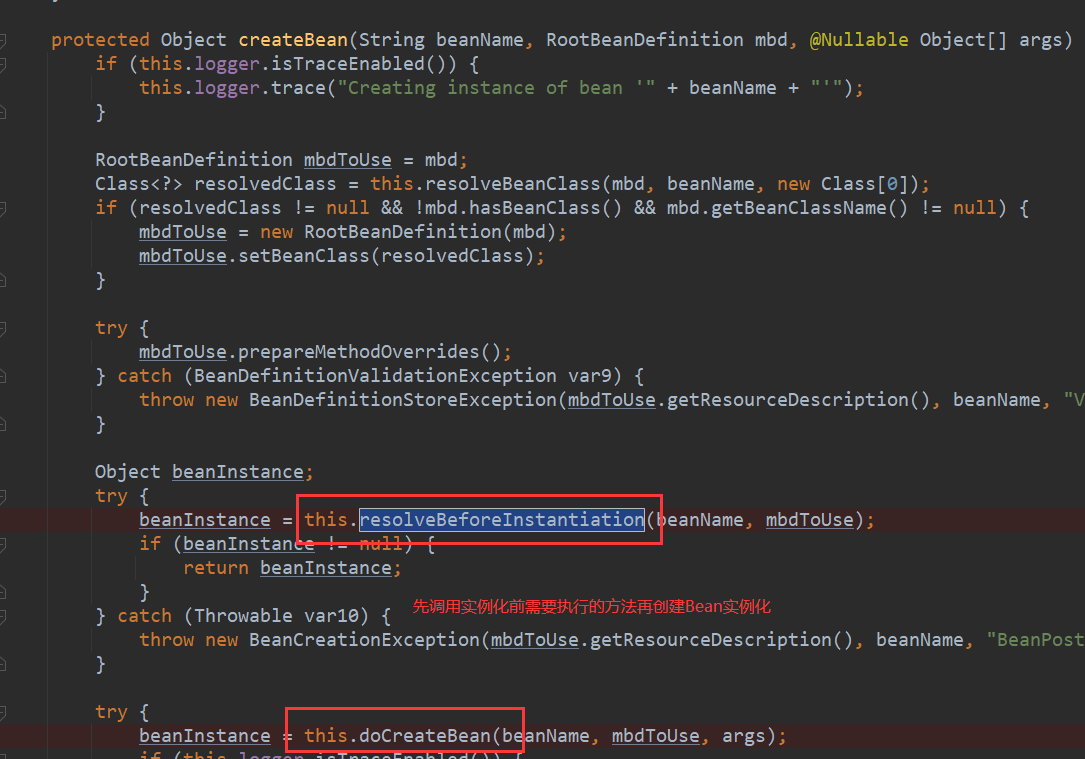
- 上一步中,没有返回代理对象,就正常执行实例化,执行doCreateBean方法实例化,然后进入属性赋值阶段
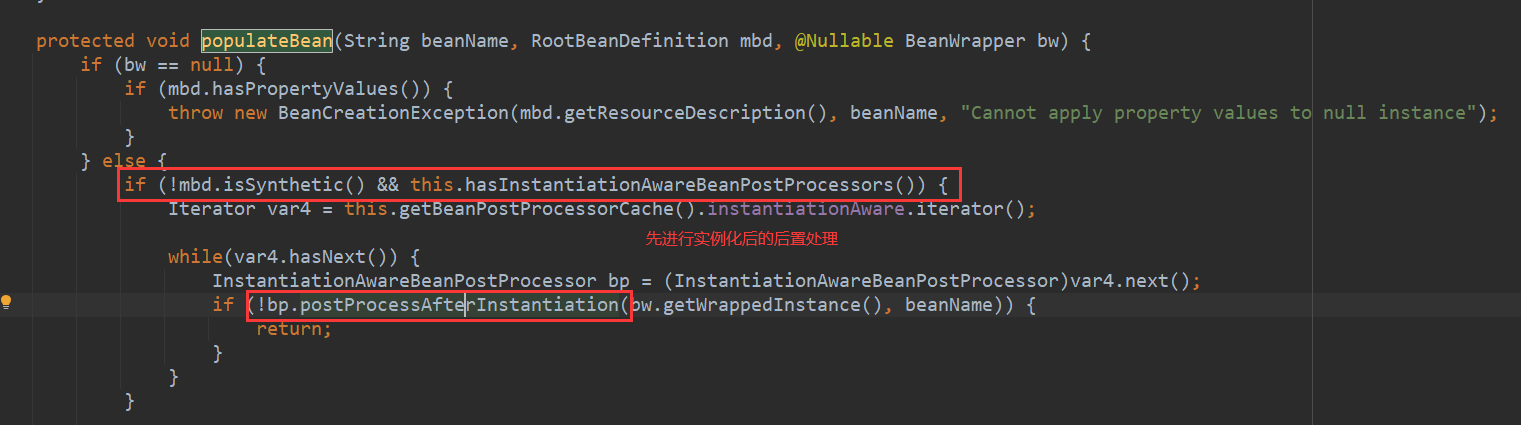
- 属性赋值阶段->populateBean(): 执行属性赋值之前,要执行Bean实例化后的后置处理postProcessAfterInstantiation,这个处理能够影响是否进行属性赋值
- 属性赋值完成后进入Bean初始化阶段->initializeBean():
- 通过initializeBean方法对Bean进行初始化,这部分初始化之前会执行实现了xxxAware接口的Bean的各个Aware方法
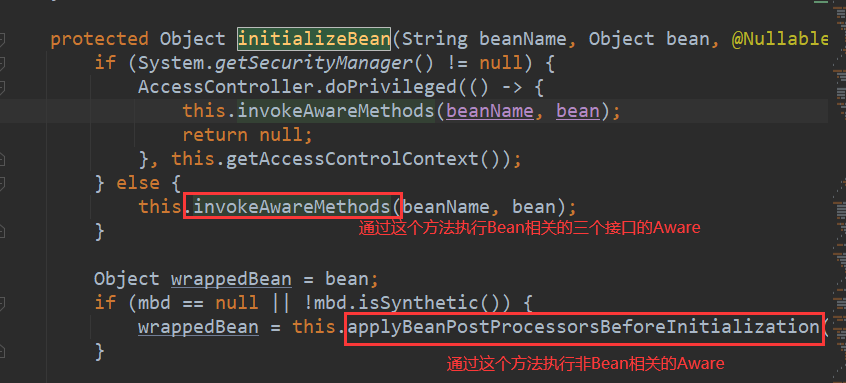
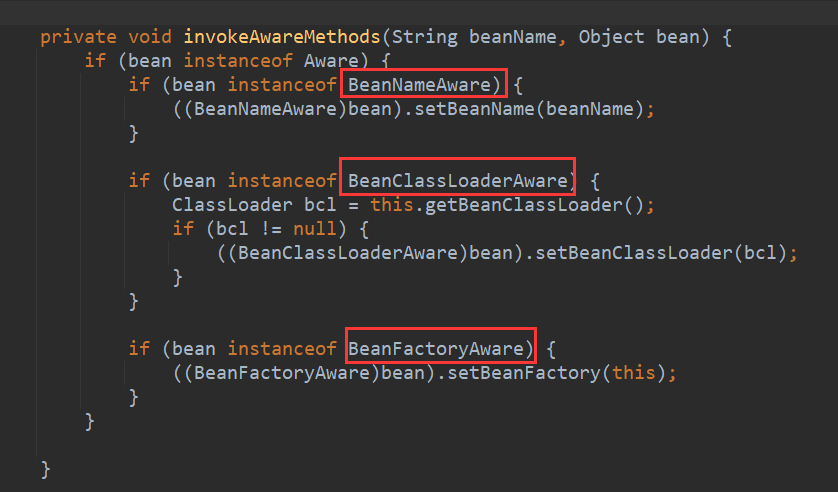
- 1.Bean相关的Aware在invokeAwareMethods中执行
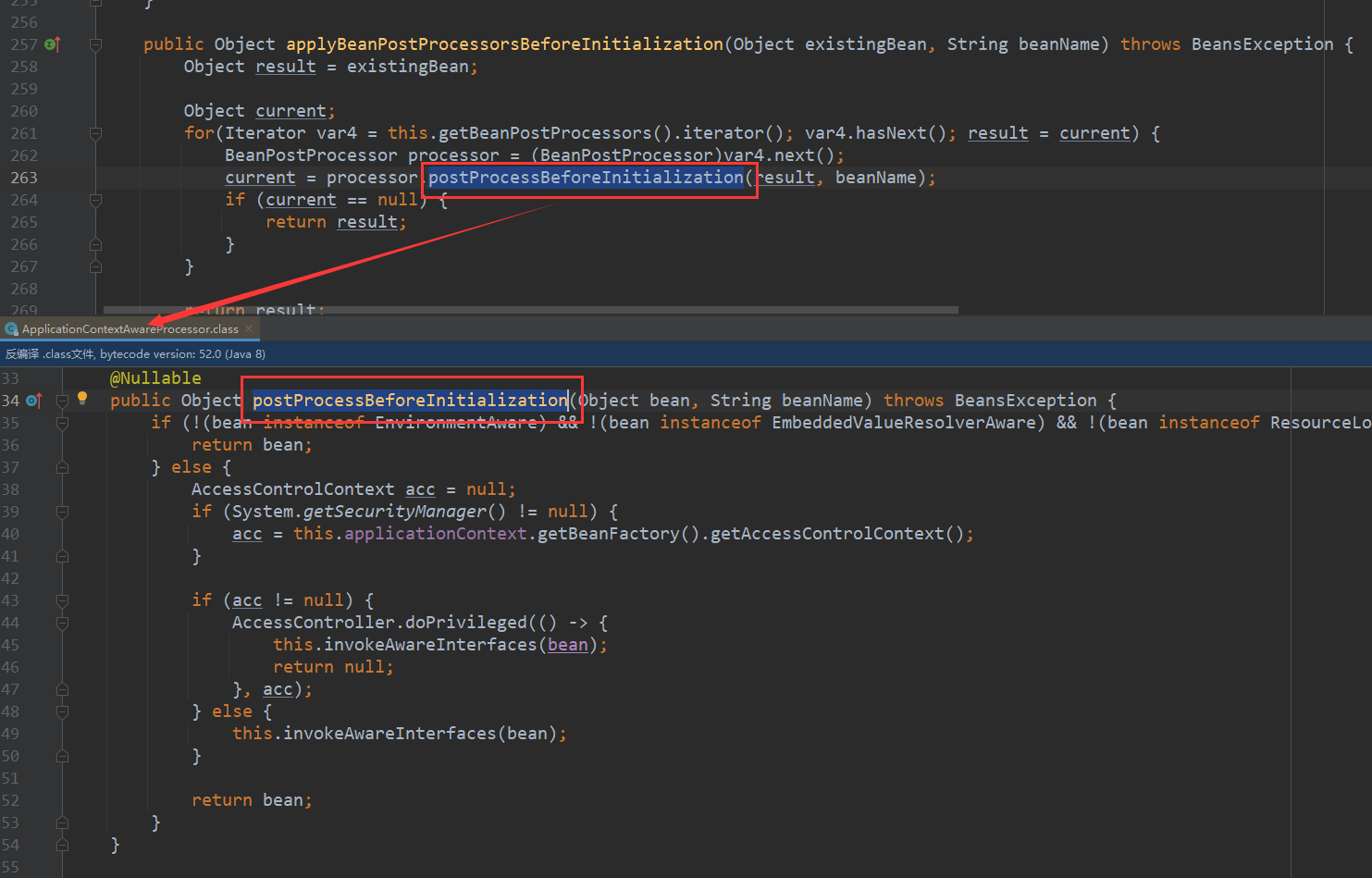
- 2.如ApplicationContextAware是通过BeanPostProcessor(ApplicationContextAwareProcessor)实现的
postProcessBeforeInitialization这里,Spring会在这个方法中决定是否返回代理对象
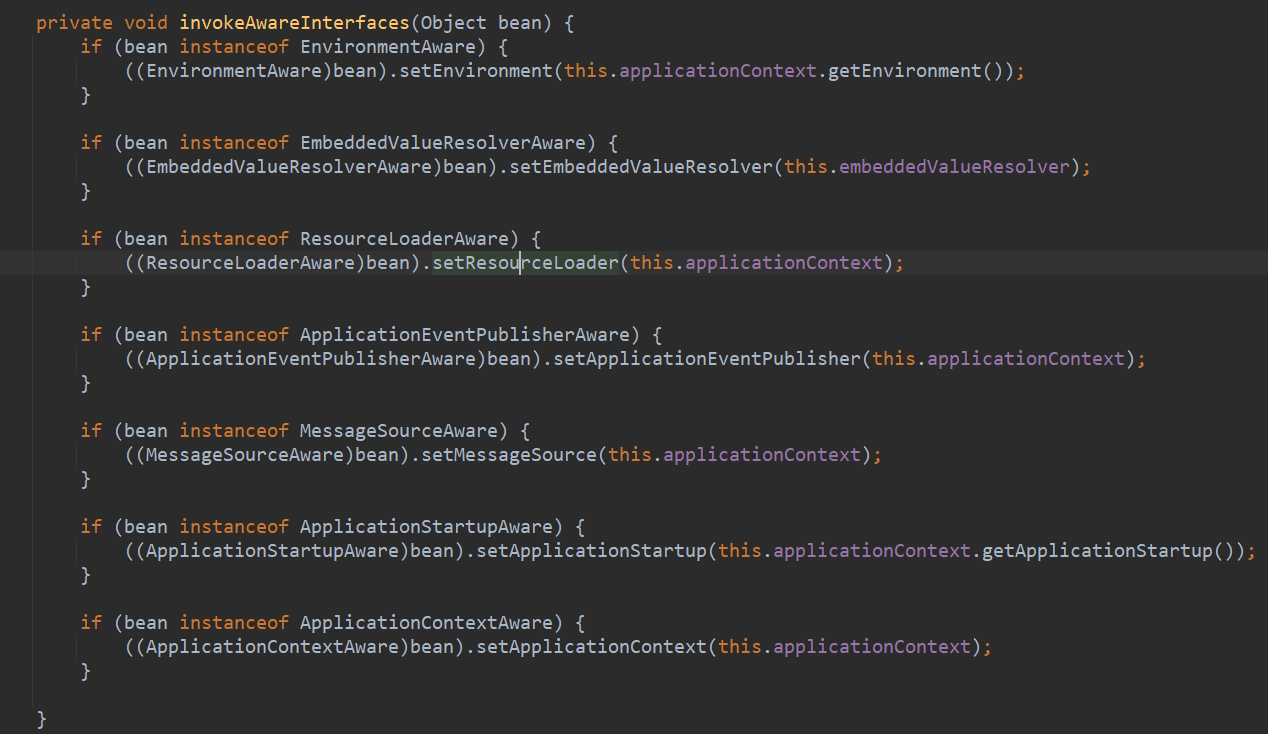
- 执行ApplicationContextAwareProcessor中的invokeAwareInterfaces对EnvironmentAware等接口方法进行调用
- 接下来就是继续在initializeBean方法中执行Bean的的初始化方法(实现了InitializingBean接口的),然后完成初始化

- 最后执行初始化完成后的动作,到此为止Bean的初始化就完成了,可以进行使用了。当然这部分流程只是大体上的,细节的循环依赖Bean的处理不在此说明
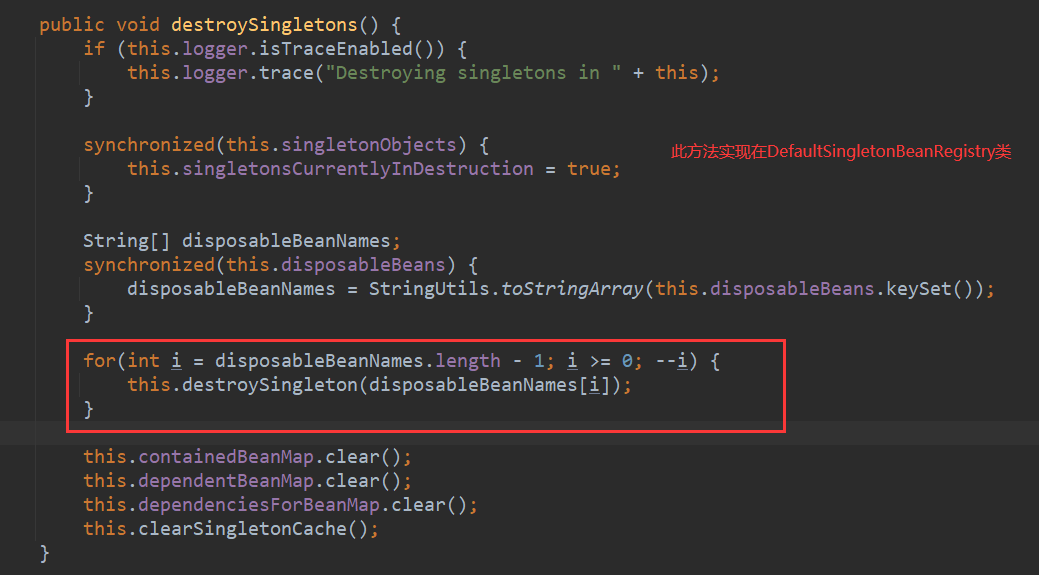
- 销毁实例阶段->DisposableBean接口
以ConfigurableApplicationContext#close()方法作为入口,实现是通过循环取所有实现了DisposableBean接口的Bean然后调用其destroy()方法
至此整个Spring Bean的声明周期就已经结束了
- 创建实例阶段->createBeanInstance():
# 循环依赖问题了解吗?
# Spring常用的注解
# 说一下Spring依赖注入的原理
- 通过xml配置文件或者注解扫描载入BeanDefinition
通过xml文件配置中对Bean的定义,或者@Configuration结合@Bean注解。
@Configuration、@Component等注解通过
ConfigurationClassPostProcessor类转变为BeanDefinition注册到BeanFactory;postProcessBeanFactory方法负责修改BeanDefinition,将@Configuration注解的类的BeanDefinition的beanClass替换为代理后的class name。

- 通过载入的BeanDefinition实例化Bean
当然在实例化之前,需要执行属性赋值,并且执行对应的Aware方法
- 对Bean的属性进行依赖注入
- 通过xml配置文件或者注解扫描载入BeanDefinition
# Spring中@Service、@Controller可以用@Component注解替换吗
# Spring怎么做到高内聚低耦合?写代码怎么体现高内聚低耦合?
# Spring Boot
# 项目
# 两次MD5加密的必要性。MD5加密是加密算法吗;你还了解过哪些加密算法;
# 介绍项目,挖掘项目,项目延伸出来的优化,一些项目中未实现的功能自己的实现思路
# 缓存和数据库的一致性问题
# 整体项目架构的介绍
# 限流算法了解哪些?(令牌桶和漏桶算法)这两者有什么区别?
# 遇到了什么坑,说说?(讲了下超时控制中的坑)
# 哪个项目做的比较满意?另一个不满意的地方在哪里?怎么优化?
# 项目的难点?遇到最大的困难是什么?
# 有考虑高并发的场景进行开发吗?
# 算法题
最长无重复子数组(LC类似题目:无重复字符的最长子串 (opens new window))
删除数组中的重复元素,返回新数组长度
手撕 反转链表2:(区间反转)
LC 滑动窗口最大值
智力题 3L和5L杯子 怎么才能盛4L水
LeetCode 124 二叉树中的最大路径和 hard
两个栈如何实现一个队列,这个队列容量是多少
LC 链表求和
求众数。要求时间复杂度O(n)和空间复杂度O(1)。(投票算法 抵消 留下的就是众数)
一个有序非重复数组,然后给定一个数,找出数组中两个数加起来等于这个数,找出它们的下标,找出多组。
给你三个有序数组,输出三个数组的公共数字
LC 三数之和
check将数组中的0元素移动到数组末尾,不改变非0元素的相对顺序 (双指针)
有序链表建立二叉搜索树
K个一组翻转链表
环链表判断 找环起点
checkLC第一题 两数之和
check回文链表
check问题:假如现在有100个人,有一个人感染了新冠肺炎,问只检测一轮(即统一去做,每个人可以做多次,但是不能等到检测结果出来再去做)的情况下,如果用最少的试剂定位到感染者?
对1~100名进行二进制编号:因为2^6 < 100 < 2^7。所以用7bit的二进制进行编号。 1号: 000 0001 2号: 000 0010 3号: 000 0011 4号: 000 0100 5号: 000 0101 6号: 000 0110 7号: 000 0111 。 。 100号: 110 0100
所以: 试剂瓶1:需要编号中bit0 为1的人一起去做检测,即1,3,5, 。。。 试剂瓶2:需要编号中bit1 为1的人一起去做检测,即2,3,6,7,。。。 试剂瓶3:需要编号中bit2 为1的人一起去做检测,即4,5,6,。。。 。。。 试剂瓶7:需要编号中bit6为1的人一起去做检测,。。。
最后,阳性为1,阴性为0,将试剂瓶的结果组成一个二进制数,试剂瓶7位最高位,试剂瓶1为最低位,得到的数字就是确认的那位。
两个线程交替打印AB
/** * @author zdk * @date 2022/4/25 13:28 */ public class PrintNumOrAB { public static void main(String[] args) { final Object lock = new Object(); new Thread(()->{ synchronized(lock){ for (int i = 0; i < 10; i++) { System.out.println(Thread.currentThread().getName()+":"+"A"); lock.notify(); try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } lock.notify(); } } },"tA").start(); new Thread(()->{ synchronized(lock){ for (int i = 0; i < 10; i++) { System.out.println(Thread.currentThread().getName()+":"+"B"); lock.notify(); try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } lock.notify(); } } },"tB").start(); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38两个线程交替打印奇偶数
/** * @author zdk * @date 2022/4/25 13:28 */ public class PrintNumOrAB { public static void main(String[] args) { final Object lock = new Object(); new Thread(()->{ synchronized(lock){ for (int i = 0; i <= 10; i+=2) { System.out.println(Thread.currentThread().getName()+":"+i); lock.notify(); try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } //最后一定要唤醒一下 否则会死锁 //因为最终运行完一定有一个线程在等待 lock.notify(); } } },"tA").start(); new Thread(()->{ synchronized(lock){ for (int i = 1; i < 10; i+=2) { System.out.println(Thread.currentThread().getName()+":"+i); lock.notify(); try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } //最后一定要唤醒一下 否则会死锁 //因为最终运行完一定有一个线程在等待 lock.notify(); } } },"tB").start(); } } //或者 @Test public void printAB(){ final Object lock = new Object(); final int[] count = {0}; new Thread(()->{ while(count[0] <10) { synchronized(lock){ if ((count[0] & 1) == 0){ System.out.println(Thread.currentThread().getName()+":"+ count[0]++); } } } },"tA").start(); new Thread(()->{ while(count[0] <10) { synchronized(lock){ if ((count[0] & 1) == 1){ System.out.println(Thread.currentThread().getName()+":"+ count[0]++); } } } },"tB").start(); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66三个线程交替打印ABC
import java.util.concurrent.locks.Condition; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock; /** * @author zdk * @date 2022/4/25 13:28 * 使用Junit跑psvm里的代码不行,必须main方法 */ @SuppressWarnings("all") public class PrintNumOrAB { public static void main(String[] args) { ABC abc = new ABC(); new Thread(() -> { for (int i = 0; i < 15; i++) { abc.printA(); } },"tA").start(); new Thread(() -> { for (int i = 0; i < 15; i++) { abc.printB(); } },"tB").start(); new Thread(() -> { for (int i = 0; i < 15; i++) { abc.printC(); } },"tC").start(); } static class ABC{ int flag = 1; final Lock lock = new ReentrantLock(); final Condition conditionA = lock.newCondition(); final Condition conditionB = lock.newCondition(); final Condition conditionC = lock.newCondition(); public void printA() { lock.lock(); try{ while (flag != 1){ conditionA.await(); } System.out.println(Thread.currentThread().getName() + ":A"); flag = 2; conditionB.signal(); }catch (Exception e){ e.printStackTrace(); }finally { lock.unlock(); } } public void printB() { lock.lock(); try{ while (flag != 2){ conditionB.await(); } System.out.println(Thread.currentThread().getName() + ":B"); flag = 3; conditionC.signal(); }catch (Exception e){ e.printStackTrace(); }finally { lock.unlock(); } } public void printC() { lock.lock(); try{ while (flag != 3){ conditionC.await(); } System.out.println(Thread.currentThread().getName() + ":C"); flag = 1; conditionA.signal(); }catch (Exception e){ e.printStackTrace(); }finally { lock.unlock(); } } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84两个线程交替打印数字、字母
/** * @author zdk * @date 2022/4/25 15:48 * 自旋方式实现交替打印 */ public class PrintNumAndAbc { static volatile int flag = 1; public static void main(String[] args) { new Thread(()->{ for (int i = 1; i <= 5; i++) { while (flag != 1){} System.out.println(Thread.currentThread().getName()+"->"+i); flag = 2; } },"t1").start(); new Thread(()->{ for (char i = 'A'; i <= 'E'; i++) { while (flag != 2){} System.out.println(Thread.currentThread().getName()+"->"+i); flag = 1; } },"t2").start(); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 反问
- 我哪些地方回答得不好
- 问了问相关的业务有哪些
- 部门业务场景
- 面试评价
- 面试什么时候出结果
- 美团对于实习生或者校招生的培养措施与方法
- 互联网寒冬看法;面试评价;培养方式
- 入职时间
- 技术栈

